The payoff
3 sessions running, 3 features in flight. Linear board updating itself. I spend most of my day reading markdowns and reviewing diffs — the actual coding part is the part I don’t do anymore. When I step away, agents keep working. When I come back, there’s a PR ready. It’s genuinely great. Also genuinely unhinged when you say it out loud to someone who doesn’t know what any of this means.
Part 1 got you started. Part 2 taught you the context game. Now let’s put it all together.
The artifact pipeline
If you take one thing from this entire series: specs before code.
Without it you get slop, enshittification, and 6k lines in the bin. With it you build production apps in languages you can’t even read.
Instead of prompting an AI to “build me X”, you create a chain of markdown artifacts where each one feeds the next:
Each phase produces a markdown file. Each phase gets a fresh context window. The artifact is the compressed knowledge that carries forward. This is the whole game.
Phase 1: Research
Dedicated session to research the problem space. Output is a markdown — how the relevant modules work, data flows, constraints.
I use a custom /research command — spawns 4 subagents in parallel, synthesizes findings into a structured markdown:
research_codebase.md — the full research command view source ↗
---
description: Document codebase as-is with comprehensive research
model: opus
---
# Research Codebase
You are tasked with conducting comprehensive research across the codebase to answer user questions by spawning parallel sub-agents and synthesizing their findings.
## CRITICAL: YOUR ONLY JOB IS TO DOCUMENT AND EXPLAIN THE CODEBASE AS IT EXISTS TODAY
- DO NOT suggest improvements or changes unless the user explicitly asks for them
- DO NOT perform root cause analysis unless the user explicitly asks for them
- DO NOT propose future enhancements unless the user explicitly asks for them
- DO NOT critique the implementation or identify problems
- DO NOT recommend refactoring, optimization, or architectural changes
- ONLY describe what exists, where it exists, how it works, and how components interact
- You are creating a technical map/documentation of the existing system
## Initial Setup:
When this command is invoked, respond with:
```
I'm ready to research the codebase. Please provide your research question or area of interest, and I'll analyze it thoroughly by exploring relevant components and connections.
```
Then wait for the user's research query.
## Steps to follow after receiving the research query:
1. **Read any directly mentioned files first:**
- If the user mentions specific files (docs, configs, TOML, JSON), read them FULLY first
- **IMPORTANT**: Use the Read tool WITHOUT limit/offset parameters to read entire files
- **CRITICAL**: Read these files yourself in the main context before spawning any sub-tasks
- This ensures you have full context before decomposing the research
2. **Analyze and decompose the research question:**
- Break down the user's query into composable research areas
- Take time to ultrathink about the underlying patterns, connections, and architectural implications the user might be seeking
- Identify specific components, patterns, or concepts to investigate
- Create a research plan using TodoWrite to track all subtasks
- Consider which directories, files, or architectural patterns are relevant
- Pay special attention to Rust-specific structures: crates, modules, traits, impls, derive macros, feature flags
3. **Spawn parallel sub-agent tasks for comprehensive research:**
- Create multiple Task agents to research different aspects concurrently
- We now have specialized agents that know how to do specific research tasks:
**For codebase research:**
- Use the **codebase-locator** agent to find WHERE files and components live
- Look for `Cargo.toml`, `lib.rs`, `main.rs`, `mod.rs` files to understand crate/module structure
- Search `*.rs` files, `build.rs`, `.cargo/config.toml`
- Use the **codebase-analyzer** agent to understand HOW specific code works (without critiquing it)
- Focus on trait definitions, impl blocks, type aliases, error types, and module hierarchies
- Use the **codebase-pattern-finder** agent to find examples of existing patterns (without evaluating them)
- Look for common Rust patterns: builder pattern, newtype pattern, From/Into impls, error handling patterns, async patterns
**IMPORTANT**: All agents are documentarians, not critics. They will describe what exists without suggesting improvements or identifying issues.
**For web research (use when external context would help):**
- Use the **web-search-researcher** agent for external documentation, crate docs, RFCs, blog posts, and resources
- Spawn web research agents proactively when the topic involves external crates, Rust language features, or ecosystem patterns
- Instruct them to return LINKS with their findings, and please INCLUDE those links in your final report
The key is to use these agents intelligently:
- Start with locator agents to find what exists
- Then use analyzer agents on the most promising findings to document how they work
- Run multiple agents in parallel when they're searching for different things
- Each agent knows its job - just tell it what you're looking for
- Don't write detailed prompts about HOW to search - the agents already know
- Remind agents they are documenting, not evaluating or improving
4. **Wait for all sub-agents to complete and synthesize findings:**
- IMPORTANT: Wait for ALL sub-agent tasks to complete before proceeding
- Compile all sub-agent results
- Connect findings across different crates, modules, and components
- Include specific file paths and line numbers for reference
- Highlight patterns, connections, and architectural decisions
- Answer the user's specific questions with concrete evidence
- Document trait relationships, generic type parameters, and lifetime annotations where relevant
5. **Generate research document:**
- Structure the document with content:
```markdown
# Research: [User's Question/Topic]
**Date**: [Current date and time]
**Git Commit**: [Current commit hash]
**Branch**: [Current branch name]
## Research Question
[Original user query]
## Summary
[High-level documentation of what was found, answering the user's question by describing what exists]
## Crate & Module Structure
[Workspace layout, crate dependencies, module tree relevant to the research]
## Detailed Findings
### [Component/Area 1]
- Description of what exists (file.rs:line)
- How it connects to other components
- Current implementation details (without evaluation)
- Key traits, types, and impls involved
### [Component/Area 2]
...
## Code References
- `path/to/file.rs:123` - Description of what's there
- `another/module/mod.rs:45-67` - Description of the code block
## Architecture Documentation
[Current patterns, conventions, and design implementations found in the codebase]
- Error handling approach (thiserror, anyhow, custom Result types)
- Async runtime usage (tokio, async-std, etc.)
- Serialization patterns (serde derives, custom impls)
- Feature flag organization
## Open Questions
[Any areas that need further investigation]
```
6. **Add GitHub permalinks (if applicable):**
- Check if on main branch or if commit is pushed: `git branch --show-current` and `git status`
- If on main/master or pushed, generate GitHub permalinks:
- Get repo info: `gh repo view --json owner,name`
- Create permalinks: `https://github.com/{owner}/{repo}/blob/{commit}/{file}#L{line}`
- Replace local file references with permalinks in the document
7. **Present findings:**
- Present a concise summary of findings to the user
- Include key file references for easy navigation
- Ask if they have follow-up questions or need clarification
8. **Handle follow-up questions:**
- If the user has follow-up questions, append to the same research document
- Add a new section: `## Follow-up Research [timestamp]`
- Spawn new sub-agents as needed for additional investigation
## Important notes:
- Always use parallel Task agents to maximize efficiency and minimize context usage
- Always run fresh codebase research - never rely solely on existing research documents
- Focus on finding concrete file paths and line numbers for developer reference
- Research documents should be self-contained with all necessary context
- Each sub-agent prompt should be specific and focused on read-only documentation operations
- Document cross-component connections and how systems interact
- Link to GitHub when possible for permanent references
- Keep the main agent focused on synthesis, not deep file reading
- Have sub-agents document examples and usage patterns as they exist
- **CRITICAL**: You and all sub-agents are documentarians, not evaluators
- **REMEMBER**: Document what IS, not what SHOULD BE
- **NO RECOMMENDATIONS**: Only describe the current state of the codebase
- **File reading**: Always read mentioned files FULLY (no limit/offset) before spawning sub-tasks
- **Rust-specific guidance**:
- Explore `Cargo.toml` and `Cargo.lock` for dependency graphs
- Map out workspace members when in a workspace
- Document `pub` visibility boundaries between modules
- Note `#[cfg(...)]` conditional compilation and feature gates
- Track `use` imports to understand module dependency flow
- Identify key derive macros and proc macros in use
- Document unsafe blocks and their safety invariants
- Note any FFI boundaries (`extern "C"`, `#[no_mangle]`)
- **Critical ordering**: Follow the numbered steps exactly
- ALWAYS read mentioned files first before spawning sub-tasks (step 1)
- ALWAYS wait for all sub-agents to complete before synthesizing (step 4)
- NEVER write the research document with placeholder values
And here’s a real output — research artifact from a trading bot project:
Example research artifact: TS Strategy ↔ Deno Runner relationship view source ↗
# Research: TS Strategy ↔ Deno Runner ↔ Session Runner Relationship
**Date**: 2026-03-12
**Git Commit**: 2d0cf45
**Branch**: main
## Research Question
How does the relationship between the TypeScript strategy and the Deno strategy runner look? Can a strategy itself declare which weather data sources (if any) it wants? Will the session runner respect that?
## Summary
Strategies are TypeScript files that run inside an embedded Deno (V8) runtime on the Rust side. Each strategy **must** declare a manifest via `ops.declareManifest({ feeds: [...] })` during `onInit`, specifying which data feeds it needs (`"book"`, `"weather"`, or both). The Rust session runner reads this manifest and respects it: events for undeclared feeds are short-circuited with empty output, never reaching the strategy's `onTick`.
---
## Architecture: Three-Layer Stack
```
┌─────────────────────────────────────────────────────┐
│ TypeScript Strategy (.ts file) │
│ Exports: onInit, onTick, onFill, onShutdown │
│ Calls: ops.declareManifest(), ops.submitIntent() │
└───────────────────┬─────────────────────────────────┘
│ serde_json serialization
┌───────────────────▼─────────────────────────────────┐
│ strategy-runtime crate (Deno embedding) │
│ DenoStrategy: transpile TS→JS, run in V8 │
│ Exposes: on_tick(), on_fill(), manifest() │
│ ops.rs: op_log, op_submit_intent, │
│ op_declare_manifest, op_store_return │
└───────────────────┬─────────────────────────────────┘
│
┌───────────────────▼─────────────────────────────────┐
│ weatherman crate (Session runner) │
│ session_init.rs: initialize_core() │
│ session_core.rs: SessionCore::process_event() │
│ session.rs: tokio::select! event loop │
└─────────────────────────────────────────────────────┘
```
---
## Layer 1: TypeScript Strategy
**Location**: `strategies/` directory
### File Layout
```
strategies/
├── lib/
│ ├── types.d.ts # IDE type declarations (TickContext, Intent, StrategyManifest, etc.)
│ ├── kelly.ts # Kelly criterion library
│ └── ensemble.ts # Ensemble analysis helpers
├── registry/
│ ├── london-weather-brackets/
│ │ ├── v1.ts
│ │ └── v2.ts # Weather + book strategy
│ └── negrisk-sum-arb/
│ └── v1.ts # Book-only strategy (no weather)
├── test-echo.ts # Test: both feeds
├── test-book-only.ts # Test: book feed only
├── test-weather-only.ts # Test: weather feed only
└── test-no-manifest.ts # Test: no manifest (should fail)
```
### Strategy API Contract
Every strategy must export `onInit(config)` and `onTick(ctx)`. Optional exports: `onMarketsReady(markets)`, `onFill(ctx, fill)`, `onShutdown()`.
**Manifest declaration** (required in `onInit`):
```typescript
export function onInit(cfg: Record<string, unknown>): StrategyParams {
ops.declareManifest({ feeds: ["weather", "book"] });
// ...
return { ensembleIqrThreshold: 2.0 };
}
```
The `StrategyManifest` type (`types.d.ts:133-135`):
```typescript
interface StrategyManifest {
feeds: ("book" | "weather")[];
}
```
**Intent submission** — strategies emit intents via `ops.submitIntent()`:
```typescript
ops.submitIntent({
kind: "order", // or "mint" or "merge"
marketId: "...",
outcome: "YES",
side: "buy",
qty: 10,
limitPx: 65,
tif: "GTC",
reason: "...",
});
```
**Tick context differentiation** — strategies distinguish weather ticks from book ticks by checking `ctx.weather`:
```typescript
export function onTick(ctx: TickContext): void {
if (ctx.weather) {
handleWeatherRefresh(ctx); // Weather data present
} else {
handleBookUpdate(ctx); // Pure book update tick
}
}
```
### `onInit` Return Value
`onInit` can optionally return a `StrategyParams` object to tune Rust-side ensemble parameters:
```typescript
interface StrategyParams {
ensembleIqrThreshold?: number;
ensembleBimodalityPenalty?: number;
}
```
These are captured by `DenoStrategy` and used by `SessionCore::fetch_weather_state()` when computing bracket probabilities (`session_core.rs:340-341`).
### Real Strategy Examples
| Strategy | Feeds | Purpose |
|----------|-------|---------|
| `london-weather-brackets/v2.ts` | `["weather", "book"]` | Weather-driven bracket trading with book depth monitoring |
| `negrisk-sum-arb/v1.ts` | `["book"]` | Pure book arbitrage, no weather needed |
| `test-book-only.ts` | `["book"]` | Test fixture for book-only feed |
| `test-weather-only.ts` | `["weather"]` | Test fixture for weather-only feed |
---
## Layer 2: Deno Strategy Runtime
**Crate**: `crates/strategy-runtime/`
**Dependencies**: `deno_core 0.390`, `deno_ast 0.53` (transpiling)
### DenoStrategy Lifecycle (`deno_strategy.rs`)
1. **`DenoStrategy::new(source_path, config)`** (`deno_strategy.rs:107-215`):
- Reads the `.ts` file from disk
- Transpiles TS→JS via `deno_ast` with content-addressed caching (`transpile.rs`)
- Creates a `JsRuntime` with the `strategy_ext` Deno extension (custom ops)
- Bootstraps `globalThis.ops` (log, submitIntent, declareManifest) and removes `globalThis.Deno` for sandboxing
- Loads the strategy as an ES module via `StrategyModuleLoader` (which sandboxes imports to `file://` within the strategies directory)
- Calls `onInit(config)` and captures the return value as `StrategyParams`
- The `StrategyManifest` is stored in Deno's `OpState` by `op_declare_manifest`
2. **`manifest()`** (`deno_strategy.rs:266-270`):
- Returns the `StrategyManifest` from `OpState` (set during `onInit` via `ops.declareManifest()`)
- If strategy never called `declareManifest`, returns `StrategyManifest::default()` (empty feeds)
3. **`on_tick(ctx)`** (`deno_strategy.rs:217-234`):
- Clears the intent collector in `OpState`
- Serializes `TickContext` to JSON and calls `globalThis.__strategy.onTick(ctx)`
- Drains and returns collected `Vec<Intent>`
4. **`on_fill(ctx, fill)`** (`deno_strategy.rs:236-247`):
- Calls `globalThis.__strategy.onFill(ctx, fill)` if exported
### Ops Bridge (`ops.rs`)
Four ops are registered in the `strategy_ext` Deno extension:
| Op | Purpose |
|----|---------|
| `op_log(level, message)` | Route strategy logs to Rust tracing |
| `op_submit_intent(intent)` | Collect an `Intent` into `Vec<Intent>` in OpState |
| `op_declare_manifest(manifest)` | Store `StrategyManifest` in OpState |
| `op_store_return(json)` | Capture return value from `onInit` |
### Module Loader & Sandboxing (`module_loader.rs`)
- Only `file://` imports are allowed (rejects `https://`, `data:`, etc.)
- Path-traversal protection: resolved imports must be within the strategies base directory (uses `canonicalize()`)
- `.ts` files are transparently transpiled via the `TranspileCache`
### Transpile Cache (`transpile.rs`)
- Content-addressed: SHA-256 of source text → cache key
- Two-tier: in-memory HashMap + disk cache with integrity checksums
- Disk cache uses domain-separated SHA-256 signatures (`weatherman-transpile-v1:`)
### Book Buffer (shared Float64Array)
Strategies that declare `"book"` in their feeds get access to `globalThis.books`, a typed accessor over a shared `Float64Array`. Layout per bracket (stride 7):
```
[bid, ask, bidQty, askQty, timestamp, bidDepthUsd, askDepthUsd]
```
Initialized by `init_book_buffer(num_brackets)` and updated by `update_book_buffer()` on the Rust side.
---
## Layer 3: Session Runner (Rust)
### Initialization (`session_init.rs:181-275`)
`initialize_core()` performs these steps:
1. **Create strategy**: `DenoStrategy::new(strategy_path, strategy_config)` — this runs `onInit`, which sets the manifest
2. **Validate manifest**: `strategy.manifest()` — **fails the session if feeds are empty** (line 210-223):
```rust
if manifest.feeds.is_empty() {
error!("strategy did not call ops.declareManifest()...");
return Err(SessionResult { ... });
}
```
3. **Init book buffer** (only if `wants_book`): `strategy.init_book_buffer(market_bindings.len())`
4. **Call onMarketsReady**: passes static market metadata to the strategy
5. **Build SessionCore**: stores `wants_book` and `wants_weather` flags
### SessionCore: Event Processing (`session_core.rs:119-193`)
`process_event()` is the central dispatch. It respects the manifest at two levels:
**WeatherTick events** (line 129-151):
```rust
SessionEvent::WeatherTick => {
if !self.wants_weather {
return Ok(TickOutput { intents: vec![], weather_state: None });
}
// fetch weather, update book buffer, build TickContext with weather, call on_tick
}
```
**BookUpdate events** (line 153-192):
```rust
SessionEvent::BookUpdate { .. } => {
if !self.wants_book {
return Ok(TickOutput { intents: vec![], weather_state: None });
}
// update single bracket in book buffer, build TickContext without weather, call on_tick
}
```
Key: `wants_book` and `wants_weather` are derived from the manifest in `SessionCore::new()` (line 91-92):
```rust
let wants_book = strategy.manifest().wants_book();
let wants_weather = strategy.manifest().wants_weather();
```
### Live Session Event Loop (`session.rs:671+`)
The `tokio::select!` loop has three branches:
1. **Time-based exit deadline** — fires once if configured
2. **Weather timer** (`interval.tick()`) — fires on the configured interval (e.g., every 5 minutes). Calls `core.process_event(SessionEvent::WeatherTick, ...)`. Even though this branch fires for all strategies, `SessionCore::process_event` short-circuits to empty output if the strategy didn't declare `"weather"`.
3. **Book update** (`book_event_rx`) — fires on WebSocket book updates. Calls `core.process_event(SessionEvent::BookUpdate { ... }, ...)`. Similarly short-circuits if strategy didn't declare `"book"`.
**Important**: The weather timer always ticks (it also serves as the market-closure polling mechanism), but the actual weather fetch and strategy callback only happen if `wants_weather` is true.
---
## The Manifest Type (Rust side)
**Location**: `crates/types/src/lib.rs:1193-1217`
```rust
#[derive(Debug, Clone, Serialize, Deserialize)]
#[serde(rename_all = "lowercase")]
pub enum Feed {
Book,
Weather,
}
#[derive(Debug, Clone, Default, Serialize, Deserialize)]
#[serde(rename_all = "camelCase")]
pub struct StrategyManifest {
#[serde(default)]
pub feeds: Vec<Feed>,
}
impl StrategyManifest {
pub fn wants_book(&self) -> bool { self.feeds.contains(&Feed::Book) }
pub fn wants_weather(&self) -> bool { self.feeds.contains(&Feed::Weather) }
}
```
---
## Answer to the Questions
### 1. How does the relationship between the TS strategy and the Deno runner look?
The TS strategy is a plain ES module file. The Rust `strategy-runtime` crate:
- Transpiles it to JS via `deno_ast`
- Runs it inside an embedded V8 via `deno_core::JsRuntime`
- Exposes `globalThis.ops` (log, submitIntent, declareManifest) as the strategy's API surface
- Calls exported functions (`onInit`, `onTick`, `onFill`, `onShutdown`, `onMarketsReady`) at the appropriate lifecycle points
- Collects `Intent` objects from `ops.submitIntent()` calls and returns them to Rust
The strategy has no direct access to Deno APIs, network, or filesystem. It communicates entirely through the ops bridge and receives data via serialized JSON arguments.
### 2. Can the strategy declare which weather data sources it wants?
**Yes.** Every strategy declares its feeds via `ops.declareManifest({ feeds: [...] })` in `onInit`. The available feed types are `"book"` and `"weather"`. A strategy can declare:
- `["book"]` — book updates only (e.g., `negrisk-sum-arb`)
- `["weather"]` — weather updates only
- `["weather", "book"]` — both (e.g., `london-weather-brackets`)
- Empty feeds → session initialization **fails** with an error
Additionally, the strategy's `onInit` return value (`StrategyParams`) can tune the Rust-side weather processing parameters (`ensembleIqrThreshold`, `ensembleBimodalityPenalty`).
However, the strategy **cannot** select specific weather models or data providers. The models fetched (GFS Seamless, ECMWF IFS025 deterministic, ECMWF IFS025 ensemble) are hardcoded in `SessionCore::fetch_weather_state()` (`session_core.rs:302-338`).
### 3. Will the session runner respect the manifest?
**Yes, fully.** The manifest is enforced at two levels:
1. **`session_init.rs`**: Empty manifest (no `declareManifest()` call) → session fails to start
2. **`session_core.rs`**: `process_event()` checks `wants_book` / `wants_weather` and short-circuits undeclared event types to `TickOutput { intents: vec![], weather_state: None }`
This means:
- A book-only strategy never triggers weather API calls
- A weather-only strategy ignores all WebSocket book updates
- Both branches always fire in the `tokio::select!` loop, but the SessionCore gate prevents unnecessary work
## Code References
- `strategies/lib/types.d.ts` — TypeScript type declarations for the strategy API
- `crates/strategy-runtime/src/deno_strategy.rs:107-215` — DenoStrategy::new lifecycle
- `crates/strategy-runtime/src/deno_strategy.rs:266-270` — manifest() accessor
- `crates/strategy-runtime/src/ops.rs:24-29` — op_declare_manifest
- `crates/types/src/lib.rs:1193-1217` — Feed enum, StrategyManifest, wants_book/wants_weather
- `crates/weatherman/src/session_init.rs:208-232` — manifest validation (empty feeds → error)
- `crates/weatherman/src/session_core.rs:79-105` — SessionCore::new captures wants_book/wants_weather
- `crates/weatherman/src/session_core.rs:119-193` — process_event short-circuits on undeclared feeds
- `crates/weatherman/src/session_core.rs:299-393` — fetch_weather_state (hardcoded models)
- `crates/weatherman/src/session.rs:671-900` — tokio::select! event loop
- `strategies/registry/negrisk-sum-arb/v1.ts:69` — book-only manifest example
- `strategies/registry/london-weather-brackets/v2.ts:179` — weather+book manifest example
You’re not implementing anything yet. Just having Claude read the codebase and explain it back to you.
Phase 2: Design doc
Feed the research to a fresh session. Brainstorm a design doc — success criteria, component overview, current vs desired state, gotchas, test cases.
Here’s a real one — P2P chunk fetching for a blockchain node. It’s long af but that’s the point:
Example design doc: PD Chunk P2P Pull view source ↗
# PD Chunk P2P Pull — Design Specification
**Date**: 2026-03-13
**Branch**: rob/pd-chunk-gossiping (off feat/pd)
**Status**: Draft
## Problem Statement
The PD (Programmable Data) service manages an in-memory chunk cache that the EVM's PD precompile reads from during transaction execution. Today, PdService is local-only: it loads chunks exclusively from the node's own StorageModules via `ChunkStorageProvider`. When a chunk is not available locally, two things break:
1. **Block validation**: A peer's block containing PD transactions is rejected as invalid. `shadow_transactions_are_valid` sends `ProvisionBlockChunks` to PdService, which responds `Err(missing)`. The block fails with `ValidationError::ShadowTransactionInvalid` — permanently, with no retry. This means a node that doesn't store the relevant data partition cannot validate blocks with PD transactions.
2. **Block building**: When a PD transaction enters the Reth mempool, `pd_transaction_monitor` fires `NewTransaction` exactly once. PdService marks the tx as `PartiallyReady` if chunks are missing. The tx is never added to `ready_pd_txs`, so the payload builder's `CombinedTransactionIterator` silently skips it on every block build attempt. There is no mechanism to re-attempt provisioning — the tx sits in `PartiallyReady` until Reth evicts it from the mempool.
Both paths need PdService to be able to fetch missing chunks from peers over the network.
## Design Decisions and Alternatives Considered
### Decision 1: Where does the blocking await happen?
**Chosen: CL/Irys side, in `shadow_transactions_are_valid`**
The block validation pipeline has two sides: the Irys consensus layer (CL) and the Reth execution layer (EL). The question was whether to block waiting for chunks on the CL side before submitting to Reth, or on the Reth side during EVM execution.
**Why not Reth side**: The PD precompile runs inside `IrysEvm::transact_raw` — fully synchronous EVM execution. `PdContext::get_chunk()` does a lock-free `DashMap::get()` and immediately returns `Ok(None)` if the chunk is missing, which causes `PdPrecompileError::ChunkNotFound`, the transaction reverts, and Reth marks the block as `PayloadStatusEnum::Invalid`. There is no async machinery inside Reth's block executor to await network fetches. Injecting one would require fundamental changes to Reth's execution model.
**Why CL side works**: `shadow_transactions_are_valid` already contains an unbounded `.await` for `wait_for_payload` (fetching EVM execution payloads from peers, with up to 10 retries at 5-second intervals). The concurrent validation `JoinSet` has no concurrency cap — blocking one block's validation task doesn't stall others. And `exit_if_block_is_too_old` races against `validate_block`, cancelling it if the tip advances more than `block_tree_depth` (50) blocks ahead, providing a natural safety net.
**Block building is unaffected**: The payload builder already gates PD tx inclusion via `ready_pd_txs.contains()`. Only transactions whose chunks are fully provisioned are included. No blocking is needed or desired in the block building path.
### Decision 2: Timeout vs. auto-cancellation
**Chosen: No explicit timeout — rely on the validation service's existing cancellation mechanism**
The validation pipeline already has `exit_if_block_is_too_old`, which races against `validate_block` via `futures::future::select`. If the canonical tip advances more than `block_tree_depth` blocks beyond the block being validated, the validation task is cancelled with `ValidationError::ValidationCancelled`. This provides a natural upper bound on how long a fetch can block.
Adding an explicit timeout would be redundant and would require choosing an arbitrary duration. The auto-cancellation mechanism is adaptive — it fires based on chain progress, not wall-clock time.
**Implementation constraint: `exit_if_block_is_too_old` is progress-based and only fires when the tip advances.** If the network is stalled (no new blocks) and peers do not serve the chunk, validation can hang indefinitely while fetch rounds keep retrying. As defense-in-depth, PdService enforces a `MAX_CHUNK_FETCH_RETRIES` per chunk key. When exceeded, the chunk is failed permanently and the block validation completes with an error. This bounds retry behavior even when the progress-based cancellation cannot fire. See the `on_fetch_done` retry path for the implementation.
PdService implements a retry loop for failed fetches: on failure, it retries with a different assigned peer via a `DelayQueue`-based backoff mechanism. The loop continues until either all chunks arrive, the request is cancelled (block validation cancelled or tx removed from mempool), or `MAX_CHUNK_FETCH_RETRIES` is exceeded.
### Decision 3: Push vs. Pull for missing PD chunks
**Chosen: Pull (request-response)**
The `feat-pd-chunks` branch contains WIP work on push-based PD chunk gossip (broadcast to all `VersionPD` peers). We chose pull instead for the following reasons:
- **Efficiency**: Push broadcasts chunks to all peers regardless of whether they need them. Pull requests only the specific chunks that are missing, from peers that are likely to have them.
- **Latency**: A node validating a block or building a block needs specific chunks now. Waiting for a peer to happen to push them is non-deterministic. Pull gives the requesting node control over timing.
- **Bandwidth**: PD chunks are 256KB each. Broadcasting every PD chunk to every peer is expensive. Pull is targeted.
- **Simplicity**: The gossip pull mechanism (`/gossip/v2/pull_data`) already exists with peer authentication, handshake, and score tracking. Adding a new request variant is minimal work.
Push-based gossip may be added later as an optimization (proactive replication), but pull is the necessary foundation for correctness.
### Decision 4: Reuse DataSyncService vs. PdService owns fetching
**Chosen: PdService owns fetching directly**
DataSyncService was evaluated as a candidate for reuse since it already pulls chunks from peers. The analysis revealed deep structural incompatibilities:
**Coupling to StorageModules**: DataSyncService's `ChunkOrchestrator` requires a local `StorageModule` instance. `ChunkOrchestrator::new` panics without a `partition_assignment`. Queue population reads SM entropy intervals. Throttling reads SM disk throughput. PD chunk requests are for arbitrary `(ledger, offset)` pairs that may not correspond to any local StorageModule.
**Peer selection by slot**: `get_best_available_peers` filters peers by `(ledger_id, slot_index)` matching a local SM's assignment. PD chunks need peers selected by the partition that contains the requested offset — a different lookup entirely.
**Completion path hardwired to SM writes**: `on_chunk_completed` unconditionally calls `sm.write_data_chunk()` and falls back to `ChunkIngressService`. PD chunks need to go into PdService's `ChunkCache` and `ChunkDataIndex` DashMap, not into StorageModules.
**Tick-based, not responsive**: DataSyncService operates on a 250ms tick cycle. PD chunk fetching for block validation needs immediate dispatch — a validation task is blocking on a oneshot response.
**Packed chunks only**: The `GET /v1/chunk/ledger/{id}/{offset}` API endpoint returns `ChunkFormat::Packed` (XOR-encrypted data). PD chunks need unpacked bytes. Adding unpacking adds latency and CPU load.
**Cross-contamination**: Sharing `PeerBandwidthManager` would mix SM sync health scores with PD fetch results, distorting both.
**Priority contention**: DataSyncService uses `UnpackingPriority::Background`. PD chunk fetching is latency-sensitive (a block validation is waiting). Sharing the unpacking queue could delay PD responses.
**Why PdService is the right owner**:
- PdService already tracks exactly which chunks are missing per tx (`TxProvisioningState.missing_chunks`)
- PdService needs to atomically transition `PartiallyReady -> Ready` and update `ready_pd_txs` + `ChunkDataIndex`
- Adding an intermediary service would be a pass-through that complicates the state machine without adding value
### Decision 5: Concurrency model within PdService
**Chosen: Structured concurrency with JoinSet owned by PdService**
PdService is currently a single-threaded actor — its `select!` loop processes messages synchronously. Three options were considered for adding async chunk fetching:
**(A) Spawn-and-callback via channel**: Spawn detached tokio tasks for HTTP fetches, each sending results back via a new internal channel. PdService's `select!` loop gains a second arm. Follows the DataSyncService pattern.
**(B) Dedicated fetcher service**: A separate long-lived `PdChunkFetcherService` task owns the HTTP client. PdService sends fetch requests, receives results. More isolation but adds cross-service coordination.
**(C) JoinSet / FuturesUnordered owned by PdService** (chosen): PdService owns a `JoinSet<PdChunkFetchResult>`. The `select!` loop polls `join_set.join_next()` alongside the message channel. This follows the same pattern as `ValidationCoordinator` which uses `JoinSet<ConcurrentValidationResult>`.
**Why JoinSet**:
- No extra channel needed — results come back directly typed
- Structured concurrency — tasks are owned by the service, automatically cancelled on shutdown when the JoinSet drops
- Clean integration with `tokio::select!` via `join_next()`
- Precedent in the codebase (`ValidationCoordinator.concurrent_tasks`)
### Decision 6: Transport mechanism for pulling chunks
**Chosen: Public HTTP API (primary) with gossip pull fallback**
Four options were considered:
**(A) Fetch packed via existing API endpoint**: Reuse `GET /v1/chunk/ledger/{id}/{offset}`. No API changes, but returns packed (XOR-encrypted) data without `tx_path`. PdService would need to send unpacking requests to the packing service, adding latency and CPU load on the requesting node. No way to verify chunk is bound to the correct ledger position.
**(B) New unpacked-only API endpoint**: Add `GET /v1/chunk/ledger/{id}/{offset}/unpacked`. The serving node always unpacks before sending. Shifts CPU cost to the data holder on every request — unpacking is expensive (entropy recomputation via C/CUDA). Does not benefit from gossip infrastructure.
**(C) Gossip pull only**: Add `PdChunk(u32, u64)` to `GossipDataRequestV2`. Leverages gossip infrastructure (peer auth, scoring, circuit breakers). However, requires gossip handshake authentication — unstaked peers (validator-only nodes) may be unable to initiate pull requests.
**(D) Existing public HTTP API with gossip fallback** (chosen): Reuse the existing `GET /v1/chunk/ledger/{id}/{offset}` endpoint as-is — no API changes. The endpoint always returns `ChunkFormat::Packed`. The requesting node unpacks locally. If the public API fails (peer offline, network error), PdService falls back to gossip pull via `GossipDataRequestV2::PdChunk`. Chunk authenticity is verified locally by the requester via `data_root` derivation from its own MDBX (see Decision 8).
**Why existing public API primary**:
- **Zero API changes**: No new endpoints, no modified responses, fully backwards compatible with all existing nodes
- **No authentication barrier**: Public API requires no gossip handshake or staking verification. Unstaked validator-only nodes can fetch chunks without special configuration.
- **Follows DataSyncService precedent**: `DataSyncService` already fetches chunks via this exact endpoint. This is the established pattern for chunk retrieval.
- **HTTP caching friendly**: Can benefit from future caching infrastructure (reverse proxy, CDN)
**Why gossip fallback**:
- Gossip pull provides an authenticated fallback with peer scoring and circuit breakers
- Useful when the public API is unreachable but the gossip connection is established
- Reuses existing `/gossip/v2/pull_data` infrastructure
**Receiver-side unpacking**: The existing endpoint always returns `ChunkFormat::Packed`. PdService unpacks locally using `irys_packing::unpack()` with entropy derived from `(packing_address, partition_hash, chunk_offset, chain_id)`. The `PackedChunk` struct carries `packing_address` and `partition_hash`, so the receiver has all necessary inputs. The existing `block_validation.rs` already handles packed chunks in its fetch path — this is an established pattern.
**TODO: Future optimization — serve unpacked when cached.** The serving node's MDBX `CachedChunks` table (populated by `ChunkIngressService`) contains unpacked versions of recently-ingested chunks. A future update should extend the endpoint (or add a new one with a query parameter like `?format=auto`) to return `ChunkFormat::Unpacked` when available, avoiding unnecessary unpacking on the receiver. This change requires a backwards-compatible wire format (e.g., new endpoint or opt-in parameter) since existing consumers expect `ChunkFormat::Packed`.
### Decision 7: Peer selection strategy
**Chosen: Targeted by partition assignment**
Three strategies were considered:
**(A) Dumb fan-out**: Ask top N active peers, first to respond wins. Simple but wastes requests to peers that don't have the data.
**(B) Targeted by partition assignment** (chosen): Compute the partition from the ledger offset using `partition_index = offset / num_chunks_in_partition`. Look up assigned miners in `canonical_epoch_snapshot().partition_assignments.data_partitions` for the relevant `(ledger_id, slot_index)`. Resolve those miners to gossip addresses via `PeerList`. Request chunks from those specific peers.
**(C) Targeted with fallback**: Try assigned miners first, fall back to fan-out. More robust but more complex.
**Why targeted**: PD chunks live at specific ledger offsets that map deterministically to partition slots. The epoch snapshot's partition assignments tell us exactly which miners are responsible for storing that data. Requesting from those miners is both efficient (high hit rate) and fast (no wasted requests).
### Decision 8: Validation of pulled chunks
**Chosen: Local `data_root` derivation + `data_path` verification**
Gossip handshake authentication (signature + staking check) provides admission control but not consensus-critical correctness. A Byzantine or compromised staker can return a valid chunk from a different ledger position — it would pass `data_path` validation against its own `data_root` but deliver wrong data for the requested offset. Since PD execution feeds directly into EVM state transitions, the requesting node must verify that the returned chunk is bound to the correct `(ledger, offset)`.
The requester derives the expected `data_root` locally from its own canonical MDBX state — no server-supplied proof (`tx_path`) is needed:
```
ledger_offset → BlockIndex::get_block_bounds() → block height
→ block_header_by_hash() → block header with ordered tx IDs
→ get_data_ledger_tx_ids_ordered(ledger) → ordered tx IDs
→ tx_header_by_txid() for each → accumulate data_size.div_ceil(chunk_size)
→ find the DataTransactionHeader that contains the target offset
→ expected_data_root = tx.data_root (from local trusted DB)
→ validate_path(expected_data_root, data_path, chunk_byte_offset) → proves chunk membership
→ SHA256(unpacked_bytes) == leaf_hash → binds raw data to proof
```
This local derivation is cryptographically equivalent to the `tx_path` proof chain used in PoA validation (`block_validation.rs:1194`) — both establish the binding from `(ledger, offset)` → `data_root`. The difference is that instead of the server providing a merkle proof (`tx_path`) from `tx_root` to `data_root`, the requester looks up the `data_root` directly from its local MDBX. Since `persist_block()` writes block headers, tx headers, and BlockIndex entries atomically in one MDBX transaction (`block_migration_service.rs:242-296`), if `get_block_bounds()` succeeds, the tx headers are guaranteed to be present. Similar DB-loading logic already exists in `load_data_transactions()` (`block_tree.rs:1518`).
**Why local derivation over server-supplied `tx_path`**:
- **Simpler wire protocol**: The server returns just the chunk data (packed or unpacked), no proof
- **No extra server-side work**: The serving node doesn't need to read `tx_path` from SM submodule DB
- **Reuses existing infrastructure**: `get_block_bounds()`, `block_header_by_hash()`, `tx_header_by_txid()` are all existing methods
- **All nodes have the data**: `persist_block()` runs on ALL nodes unconditionally (no role/pledge/miner gating) — validator-only nodes have the same MDBX state
- **Same trust model**: Both `tx_root` (from BlockIndex) and `data_root` (from tx headers) come from the same canonical migrated state
**BlockIndex availability guarantee**: The BlockIndex always has the committing block when a PD tx references that offset. `persist_block()` atomically writes the block header, tx headers, and BlockIndex entry. Only afterward does `ChunkMigrationService::BlockMigrated` fire to write chunk data into storage modules. Since PD txs can only reference chunks that exist in storage, and chunks only exist in storage after migration, the committing block is guaranteed to be in the BlockIndex. (`PD-readable ⟹ BlockIndex present` is always true.)
**Batch optimization**: When fetching multiple chunks from the same block, the `get_block_bounds()` and tx header lookups can be cached — the `data_root` resolution only needs to happen once per DataTransaction boundary.
## Architecture
### Component Diagram
```
PdService (single actor, owns JoinSet)
┌─────────────────────────────────────────────┐
│ │
pd_transaction_monitor │ select! { │
───NewTransaction────> │ shutdown, │
│ msg_rx.recv() => handle_message(), │
shadow_txs_are_valid │ join_set.join_next() => on_fetch_done(), │
──ProvisionBlockChunks>│ } │
│ │
pd_transaction_monitor │ State: │
──TransactionRemoved──>│ cache: ChunkCache (LRU + DashMap mirror) │
│ tracker: ProvisioningTracker │
PdBlockGuard::drop() │ pending_fetches: HashMap<ChunkKey, ...> │
──ReleaseBlockChunks──>│ pending_blocks: HashMap<B256, ...> │
│ join_set: JoinSet<PdChunkFetchResult> │
│ │
│ New deps: │
│ http_client: reqwest::Client │
│ gossip_client: GossipClient │
│ peer_list: PeerList │
│ block_tree: BlockTreeReadGuard │
│ consensus_config: ConsensusConfig │
└──────────────────┬──────────────────────────┘
│ spawns fetch tasks
▼
┌─────────────────────────────────────────────┐
│ Fetch Task (runs in JoinSet) │
│ │
│ 1. Compute partition from (ledger, offset) │
│ 2. Look up assigned miners (epoch snapshot)│
│ 3. Resolve to peer addresses (PeerList) │
│ 4. Try public API first (existing endpoint):│
│ GET /v1/chunk/ledger/{id}/{off} │
│ → always returns Packed │
│ 5. If API fails, fall back to gossip pull: │
│ /gossip/v2/pull_data (PdChunk variant) │
│ → returns Unpacked (cache hit) or Packed│
│ 6. If packed: unpack locally │
│ 7. Return PdChunkFetchResult (ChunkFormat) │
└──────────────────┬──────────────────────────┘
│
▼
┌─────────────────────────────────────────────┐
│ Serving Peer │
│ │
│ Public API: GET /v1/chunk/ledger/{id}/{off}│
│ (existing endpoint, no changes) │
│ → always returns ChunkFormat::Packed │
│ │
│ Gossip fallback: resolve_data_request │
│ PdChunk(ledger, offset) => │
│ get_chunk_for_pd (unpacked or packed) │
└─────────────────────────────────────────────┘
```
### Data Flow: Block Validation Path
```
Peer block arrives with PD transactions
│
▼
BlockDiscoveryService::block_discovered (pre-validation)
│
▼
BlockTreeService::on_block_prevalidated
│
▼
ValidationService::ValidateBlock
│
▼
BlockValidationTask::execute_concurrent
│
├── futures::select(validate_block(), exit_if_block_is_too_old())
│
▼
validate_block():
let cancel = CancellationToken::new();
All 6 tasks wrapped with with_cancel(task, cancel.clone()):
- Each task signals cancel.cancel() on definitive failure
- Each task listens for cancel.cancelled() from siblings
tokio::join!(
with_cancel(recall_task, cancel),
with_cancel(poa_task, cancel),
shadow_tx_task (cancel-aware), ◄── PD chunk provisioning happens here
with_cancel(seeds_task, cancel),
with_cancel(commitment_task, cancel),
with_cancel(data_txs_task, cancel)
)
│
▼
shadow_transactions_are_valid:
1. wait_for_payload (existing, may block for EVM payload)
2. Extract PdChunkSpecs from block's PD transactions
3. Send ProvisionBlockChunks { block_hash, chunk_specs, response } to PdService
4. .await on oneshot response ◄── BLOCKS HERE until chunks fetched
│ or cancelled by exit_if_block_is_too_old
▼
PdService::handle_provision_block_chunks:
1. Convert specs to ChunkKeys via specs_to_keys()
2. For each key:
a. Cache hit → add_reference(key, block_hash)
b. Cache miss, local storage hit → cache.insert, add to DashMap
c. Cache miss, local storage miss → add to missing set
3. If no missing chunks → respond Ok(()), create block_tracker entry
4. If missing chunks:
a. Store oneshot in pending_blocks[block_hash]
b. For each missing key: register in pending_fetches, spawn fetch task
c. Return (don't respond yet — oneshot held open)
│
▼ (async, via JoinSet)
Fetch tasks execute:
1. Compute partition_index = offset / num_chunks_in_partition
2. Look up assigned miners from epoch snapshot
3. Resolve to peer addresses (PeerList) — both API and gossip addresses
4. For each assigned peer (in order):
a. Try public API first: GET http://{peer.api}/v1/chunk/ledger/{id}/{off}
b. If API fails (timeout, 404, network error): try gossip fallback
gossip_client.pull_data(peer, PdChunk(ledger, offset))
c. If Ok(Some(chunk_format)): return Ok(result)
d. If both fail: try next peer
5. If all peers exhausted: return Err(AllPeersFailed)
│
▼
PdService::on_fetch_done (select! arm 3):
On Ok(chunk_format):
1. If packed, unpack locally; if already unpacked (gossip cache hit), use directly:
Packed → irys_packing::unpack() using PackedChunk metadata
Unpacked → use bytes directly
2. Derive expected data_root locally from MDBX:
a. bounds = block_index.get_block_bounds(DataLedger::Publish, key.offset)
b. block_header = block_header_by_hash(bounds.block_hash)
c. tx_ids = block_header.get_data_ledger_tx_ids_ordered(DataLedger::Publish)
d. Walk tx_ids, load each DataTransactionHeader, accumulate
data_size.div_ceil(chunk_size) to find the tx containing key.offset
e. expected_data_root = matching_tx.data_root
3. Verify chunk against expected data_root:
a. Ensure chunk.data_root == expected_data_root
b. validate_path(expected_data_root, &chunk.data_path, chunk_byte_offset_in_tx)
→ confirms chunk membership under data_root
c. SHA256(unpacked_bytes) == leaf_hash → binds raw data to proof
d. On verification failure: mark peer as invalid, retry with different peer
2. Insert chunk bytes into cache with explicit reference per waiter:
a. Pick first waiter (tx or block) as the initial reference:
cache.insert(key, data, first_waiter_id)
b. For each additional waiting block:
cache.add_reference(key, block_hash)
c. For each additional waiting tx:
cache.add_reference(key, tx_hash)
(This ensures every consumer holds a reference — a later
TransactionRemoved or ReleaseBlockChunks cannot drop the only
reference while other consumers still depend on the chunk.)
3. Remove key from pending_fetches, consuming the PdChunkFetchState
4. For each waiting block in the consumed state's waiting_blocks:
a. Remove key from pending_blocks[block_hash].remaining_keys
b. If remaining_keys is empty:
- Respond Ok(()) on the stored oneshot
- Move chunk_keys to block_tracker (same as today's success path)
5. For each waiting tx in the consumed state's waiting_txs:
a. Remove key from tracker[tx_hash].missing_chunks
b. If missing_chunks is empty:
- Transition state to Ready
- Insert tx_hash into ready_pd_txs
On Err(AllPeersFailed { excluded_peers }):
1. Check if any waiters remain (block oneshots not closed, txs not removed)
2. If no waiters remain: remove from pending_fetches, skip retry
3. If MAX_CHUNK_FETCH_RETRIES exceeded: fail_chunk_permanently(key)
4. If waiters remain and retries not exceeded:
a. Compute backoff delay: min(1s * 2^attempt, 30s)
b. Insert RetryEntry into retry_queue (DelayQueue)
c. Store delay_queue::Key in PdChunkFetchState
d. Transition status to FetchPhase::Backoff
PdService::on_retry_ready (select! arm 4, fires when DelayQueue timer expires):
1. Validate generation matches (skip if stale)
2. Check waiters still exist (skip if all removed during backoff)
3. Re-resolve peers via resolve_peers_for_chunk (picks up epoch changes)
4. Spawn new fetch task into JoinSet
5. Store AbortHandle in PdChunkFetchState
6. Transition status to FetchPhase::Fetching
│
▼
shadow_transactions_are_valid receives Ok(()) on the oneshot
→ Creates PdBlockGuard (RAII, sends ReleaseBlockChunks on drop)
→ Continues with shadow tx structural validation
→ Returns (execution_data, pd_guard)
│
▼
All 6 tasks complete via tokio::join!
→ If all Valid: submit_payload_to_reth (Reth executes, precompile reads DashMap)
→ PdBlockGuard drops → ReleaseBlockChunks → cache references decremented
```
### Data Flow: Mempool Path
```
PD transaction enters Reth mempool
│
▼
pd_transaction_monitor detects PD header + access list
→ PdChunkMessage::NewTransaction { tx_hash, chunk_specs }
│
▼
PdService::handle_provision_chunks:
1. Duplicate guard: if tracker.get(&tx_hash).is_some() → return
2. Convert specs to ChunkKeys
3. Register in tracker (state = Provisioning)
4. For each key:
a. Cache hit → add_reference
b. Local storage hit → cache.insert
c. Local storage miss → add to missing set
5. If no missing → state = Ready, ready_pd_txs.insert(tx_hash)
6. If missing:
a. state = PartiallyReady { found, total }
b. For each missing key: register in pending_fetches, spawn fetch task
c. Return (tx stays PartiallyReady)
│
▼ (async, via JoinSet — same as block validation path)
Fetch tasks execute and return results
│
▼
PdService::on_fetch_done:
→ Insert chunk into cache
→ Update all waiting txs
→ When last missing chunk arrives for a tx:
state = Ready, ready_pd_txs.insert(tx_hash)
│
▼
Next block build attempt:
CombinedTransactionIterator::next()
→ ready_pd_txs.contains(&tx_hash) → true
→ PD transaction included in block
→ EVM executes → PD precompile reads from DashMap → succeeds
```
### Data Flow: Cancellation
```
Case 1: Block validation cancelled (tip advanced too far)
─────────────────────────────────────────────────────────
exit_if_block_is_too_old resolves first in futures::select
→ validate_block future dropped
→ oneshot receiver dropped (shadow_tx_task was awaiting it)
│
▼
PdService tries to send Ok(()) on stored oneshot → SendError
→ Remove pending_blocks[block_hash] entry
→ Decrement cache references for any already-fetched chunks
→ Remove block_hash from pending_fetches[key].waiting_blocks
→ If no other waiters for those keys:
Fetching → abort_handle.abort() (cancels in-flight fetch task)
Backoff → retry_queue.remove(&queue_key) (cancels pending timer)
→ cache.try_shrink_to_fit()
Case 2: Mempool transaction removed
────────────────────────────────────
pd_transaction_monitor fires TransactionRemoved
→ PdService::handle_release_chunks (existing logic)
→ Additionally: remove tx_hash from pending_fetches[key].waiting_txs
→ If no other waiters for those keys:
Fetching → abort_handle.abort()
Backoff → retry_queue.remove(&queue_key)
→ Decrement cache references, evict unreferenced chunks
→ cache.try_shrink_to_fit()
Case 3: Sibling validation task fails (CancellationToken)
──────────────────────────────────────────────────────────
A sibling task (e.g., PoA) completes with Invalid
→ with_cancel wrapper calls cancel.cancel()
→ CancellationToken wakes all sibling cancelled() futures
→ shadow_tx_task's select! picks cancelled() → drops inner future
→ oneshot receiver dropped (was awaiting ProvisionBlockChunks response)
│
▼
Same cascade as Case 1:
PdService detects dropped oneshot → abort_handle.abort() or
retry_queue.remove() → eager cleanup of in-flight work
with_cancel helper (used to wrap each validation task uniformly):
async fn with_cancel(
fut: impl Future<Output = ValidationResult>,
cancel: CancellationToken,
) -> ValidationResult {
tokio::select! {
result = fut => {
if matches!(&result, ValidationResult::Invalid(_)) {
cancel.cancel();
}
result
}
_ = cancel.cancelled() => {
ValidationResult::Invalid(ValidationError::ValidationCancelled {
reason: "sibling validation failed".into(),
})
}
}
}
shadow_tx_task uses a similar pattern but with eyre::Result return type:
let shadow_tx_task = {
let cancel = cancel.clone();
async move {
tokio::select! {
result = shadow_tx_task => {
if result.is_err() { cancel.cancel(); }
result
}
_ = cancel.cancelled() => {
Err(eyre::eyre!("cancelled: sibling validation task failed"))
}
}
}
};
No signature changes: the token is created and consumed entirely within
validate_block(). No changes to shadow_transactions_are_valid, poa_is_valid,
or any other validation function signature.
Case 4: PdService shutdown
──────────────────────────
PdService select! loop exits on shutdown signal
→ JoinSet drops → all in-flight fetch tasks cancelled automatically
→ DelayQueue drops → all pending retry timers cancelled
→ No cleanup needed (structured concurrency)
```
## Internal State Changes
### New Types in PdService
```rust
/// Result returned by a chunk fetch task in the JoinSet.
/// ChunkFormat is Unpacked (from gossip MDBX cache hit) or Packed (from API / gossip SM fallback).
struct PdChunkFetchResult {
key: ChunkKey,
result: Result<ChunkFormat, PdChunkFetchError>,
}
/// Phase of a single chunk key's fetch lifecycle.
enum FetchPhase {
/// An HTTP fetch task is running in the JoinSet.
Fetching,
/// Waiting for the backoff timer to expire in the DelayQueue.
Backoff,
}
/// Tracks an in-flight or retrying fetch for a single ChunkKey.
struct PdChunkFetchState {
/// Mempool transactions waiting on this chunk.
waiting_txs: HashSet<B256>,
/// Block validations waiting on this chunk.
waiting_blocks: HashSet<B256>,
/// Number of fetch attempts so far (incremented on each retry).
attempt: u32,
/// Distinguishes provisioning lifecycles. Incremented when a key
/// re-enters Fetching after being cleaned up and reprovisioned.
/// Prevents stale retry timers from acting on a new lifecycle.
generation: u64,
/// Peers that have been tried and failed (passed to the next fetch task).
excluded_peers: HashSet<IrysAddress>,
/// Current phase of the fetch lifecycle.
status: FetchPhase,
/// Handle to cancel the in-flight fetch task (when status == Fetching).
/// Stored from JoinSet::spawn's return value. Used for eager cancellation
/// when all waiters are removed — call abort_handle.abort() to cancel
/// the in-flight HTTP request immediately.
abort_handle: Option<AbortHandle>,
/// Handle to cancel the pending retry timer (when status == Backoff).
/// Used for eager cancellation via retry_queue.remove(&queue_key).
retry_queue_key: Option<delay_queue::Key>,
}
/// Entry stored in the DelayQueue for scheduled retries.
struct RetryEntry {
key: ChunkKey,
attempt: u32,
generation: u64,
excluded_peers: HashSet<IrysAddress>,
}
/// Tracks a block validation waiting for chunks to be fetched.
struct PendingBlockProvision {
/// Chunks still missing for this block.
remaining_keys: HashSet<ChunkKey>,
/// All chunk keys for this block (for reference cleanup).
all_keys: Vec<ChunkKey>,
/// The oneshot sender to respond on when all chunks arrive.
response: oneshot::Sender<Result<(), Vec<(u32, u64)>>>,
}
```
### Modified PdService Struct
```rust
pub struct PdService {
// Existing fields
shutdown: Shutdown,
msg_rx: PdChunkReceiver,
cache: ChunkCache,
tracker: ProvisioningTracker,
storage_provider: Arc<dyn ChunkStorageProvider>,
block_tracker: HashMap<B256, Vec<ChunkKey>>,
ready_pd_txs: Arc<DashSet<B256>>,
// New fields
join_set: JoinSet<PdChunkFetchResult>,
retry_queue: DelayQueue<RetryEntry>,
pending_fetches: HashMap<ChunkKey, PdChunkFetchState>,
pending_blocks: HashMap<B256, PendingBlockProvision>,
http_client: reqwest::Client, // for public API fetch (primary)
gossip_client: GossipClient, // for gossip pull (fallback)
peer_list: PeerList,
block_tree: BlockTreeReadGuard,
block_index: BlockIndexReadGuard, // for local data_root derivation (get_block_bounds)
db: DatabaseProvider, // for tx header lookups (block_header_by_hash, tx_header_by_txid)
num_chunks_in_partition: u64,
}
```
### Modified Event Loop
Active fetches live in a `JoinSet`; retry timers live in a `tokio_util::time::DelayQueue` owned by the actor. This separates retry scheduling from fetch execution — retries are data in a queue, not detached tasks or sleeping sentinels mixed with fetch results.
```rust
async fn start(mut self) {
loop {
tokio::select! {
biased;
_ = &mut self.shutdown => { break; }
msg = self.msg_rx.recv() => {
match msg {
Some(message) => self.handle_message(message),
None => { break; }
}
}
Some(result) = self.join_set.join_next() => {
self.on_fetch_done(result);
}
Some(expired) = self.retry_queue.next(), if !self.retry_queue.is_empty() => {
self.on_retry_ready(expired.into_inner());
}
}
}
}
```
**`on_fetch_done` retry path** (pseudocode):
```rust
fn on_fetch_done(&mut self, result: JoinResult<PdChunkFetchResult>) {
let PdChunkFetchResult { key, result } = /* unwrap join result */;
match result {
Ok(chunk_format) => { /* unpack if packed, derive expected data_root from MDBX, verify, cache chunk, notify waiters */ }
Err(PdChunkFetchError::AllPeersFailed { excluded_peers }) => {
let Some(state) = self.pending_fetches.get_mut(&key) else { return };
// No waiters left — skip retry, clean up
if state.waiting_txs.is_empty() && state.waiting_blocks.is_empty() {
self.pending_fetches.remove(&key);
return;
}
// Exceeded max retries — fail permanently
if state.attempt >= MAX_CHUNK_FETCH_RETRIES {
self.fail_chunk_permanently(key);
return;
}
// Schedule retry via DelayQueue
let delay = backoff_duration(state.attempt); // min(1s * 2^attempt, 30s)
let retry_entry = RetryEntry {
key,
attempt: state.attempt + 1,
generation: state.generation,
excluded_peers,
};
let queue_key = self.retry_queue.insert(retry_entry, delay);
state.attempt += 1;
state.status = FetchPhase::Backoff;
state.retry_queue_key = Some(queue_key);
state.abort_handle = None; // no in-flight task during backoff
state.excluded_peers = excluded_peers;
}
}
}
```
**`on_retry_ready` handler** (pseudocode):
```rust
fn on_retry_ready(&mut self, entry: RetryEntry) {
let Some(state) = self.pending_fetches.get_mut(&entry.key) else { return };
// Stale generation — this retry belongs to an old provisioning lifecycle
if state.generation != entry.generation { return; }
// Waiters vanished during backoff
if state.waiting_txs.is_empty() && state.waiting_blocks.is_empty() {
self.pending_fetches.remove(&entry.key);
return;
}
// Re-resolve peers (picks up epoch changes, new peers coming online)
let peers = self.resolve_peers_for_chunk(&entry.key, &entry.excluded_peers);
let abort_handle = self.join_set.spawn(
fetch_chunk_from_peers(entry.key, peers, self.gossip_client.clone())
);
state.status = FetchPhase::Fetching;
state.abort_handle = Some(abort_handle);
state.retry_queue_key = None;
}
```
**Cancellation path**: When all waiters for a key are removed (tx removed + block released), PdService checks `status`:
- `Fetching` → call `abort_handle.abort()` to cancel the in-flight fetch task
- `Backoff` → call `self.retry_queue.remove(&queue_key)` to cancel the pending timer
Both are eager cancellation — no dangling tasks or timers survive waiter cleanup. Pending retries are entries in a queue, not spawned tasks. Queue length is bounded by the number of tracked chunk keys.
### Partition-to-Peer Resolution
**Ledger ID**: Currently, `specs_to_keys()` hardcodes `ledger: 0` for all PD chunks (`pd_service.rs:155`). All PD chunk data lives on the Publish ledger (ledger 0). The `GossipDataRequestV2::PdChunk(u32, u64)` carries the ledger ID for forward-compatibility, but in practice it will be 0. The `resolve_peers_for_chunk` method uses the Publish ledger (`DataLedger::Publish`) for partition assignment lookups.
**Partition assignment lookup**: The `PartitionAssignments::data_partitions` is a `BTreeMap<PartitionHash, PartitionAssignment>` keyed by partition hash, not by index. To find which miners are assigned to the partition containing a given offset, we must iterate the entries and filter by matching `ledger_id` and computed `slot_index`. The `slot_index` is derived from the ledger offset: `slot_index = offset / num_chunks_in_partition`. Each `PartitionAssignment` has a `slot_index` field that can be compared.
**Self-peer filtering**: The resolved peer list must exclude the node's own miner address to avoid requesting chunks from itself.
```rust
fn resolve_peers_for_chunk(&self, key: &ChunkKey) -> Vec<PeerAddress> {
let slot_index = key.offset / self.num_chunks_in_partition;
let ledger_id = DataLedger::Publish;
let epoch_snapshot = self.block_tree.canonical_epoch_snapshot();
let assignments = &epoch_snapshot.partition_assignments.data_partitions;
let mut peers = Vec::new();
for (_hash, assignment) in assignments.iter() {
if assignment.ledger_id == Some(ledger_id)
&& assignment.slot_index == slot_index
&& assignment.miner_address != self.own_miner_address // filter self
{
if let Some(peer) = self.peer_list.peer_by_mining_address(&assignment.miner_address) {
peers.push(peer.address.clone());
}
}
}
peers
}
```
**Epoch snapshot choice**: We use `canonical_epoch_snapshot()` (the snapshot from the canonical chain tip) rather than a fork-specific snapshot. This is correct because we are looking up which miners *store* data, not validating consensus. Storage assignments are determined by the canonical chain regardless of which fork a block being validated is on.
### Fetch Deduplication
When multiple transactions or blocks need the same chunk:
```
NewTransaction(tx_A) needs chunks [C1, C2, C3]
→ C1: not in pending_fetches → spawn fetch, register tx_A as waiter
→ C2: not in pending_fetches → spawn fetch, register tx_A as waiter
→ C3: not in pending_fetches → spawn fetch, register tx_A as waiter
ProvisionBlockChunks(block_X) needs chunks [C2, C4]
→ C2: already in pending_fetches (InFlight) → just add block_X as waiter
→ C4: not in pending_fetches → spawn fetch, register block_X as waiter
When C2 fetch completes:
→ Insert into cache
→ Update tx_A: remove C2 from missing_chunks (2 remaining: C1, C3)
→ Update block_X: remove C2 from remaining_keys (1 remaining: C4)
```
## Public API Endpoint
### Existing Route: `GET /v1/chunk/ledger/{ledger_id}/{offset}` (no changes)
PdService uses the existing public chunk endpoint as-is. No modifications to the endpoint, handler, or `ChunkStorageProvider` trait are needed.
The existing endpoint always returns `ChunkFormat::Packed(PackedChunk)` (`get_chunk.rs:34`). The `PackedChunk` includes all metadata needed by the requester: `data_root`, `data_size`, `data_path` (merkle proof), `packing_address`, `partition_hash`, `partition_offset`.
The requester unpacks locally using `irys_packing::unpack()` and verifies the chunk against a locally-derived `data_root` (see Decision 8).
**Implementation constraint: Rate limiting.** The existing chunk endpoint has no rate limiting. Bulk PD chunk fetching during block validation could overload peers. Options for future hardening: (a) add a semaphore similar to `chunk_semaphore` used for inbound chunk gossip, (b) leverage Actix middleware for per-peer rate limiting.
**TODO: Future optimization — serve unpacked when cached.** The serving node's MDBX `CachedChunks` table (populated by `ChunkIngressService`) contains unpacked versions of recently-ingested chunks. A future update should add a new endpoint or query parameter (e.g., `?format=auto`) to return `ChunkFormat::Unpacked` when available, avoiding unnecessary unpacking on the receiver. This must be backwards-compatible since existing consumers expect `ChunkFormat::Packed`.
## Gossip Protocol Changes (Fallback Path)
### Wire Type Additions (`crates/types/src/gossip.rs`)
The gossip pull path serves as a fallback when the public API is unreachable.
```rust
// Add to GossipDataRequestV2:
pub enum GossipDataRequestV2 {
ExecutionPayload(B256),
BlockHeader(BlockHash),
BlockBody(BlockHash),
Chunk(ChunkPathHash),
Transaction(H256),
PdChunk(u32, u64), // NEW: (ledger_id, ledger_offset)
}
// V1 compatibility:
impl GossipDataRequestV2 {
pub fn to_v1(&self) -> Option<GossipDataRequestV1> {
match self {
// ... existing variants ...
Self::PdChunk(..) => None, // V1 peers cannot serve PD chunks
}
}
}
// Add to GossipDataV2 (response enum):
pub enum GossipDataV2 {
// ... existing variants (ExecutionPayload, BlockHeader, BlockBody, Chunk, Transaction) ...
PdChunk(ChunkFormat), // NEW: unpacked from MDBX cache if available, packed otherwise
}
```
### Gossip Serving Handler (`crates/p2p/src/gossip_data_handler.rs`)
`resolve_data_request` gains a new match arm using the same `get_chunk_with_tx_path` trait method:
```rust
GossipDataRequestV2::PdChunk(ledger, offset) => {
// Try MDBX CachedChunks first for unpacked version, fall back to packed from SM
match self.storage_provider.get_chunk_for_pd(ledger, offset.into()) {
Ok(Some(chunk_format)) => {
Some(GossipDataV2::PdChunk(chunk_format))
}
Ok(None) => None,
Err(e) => {
warn!(ledger, offset, "Error serving PD chunk: {}", e);
None
}
}
}
```
This requires a new method `get_chunk_for_pd` on `ChunkStorageProvider` that checks the MDBX `CachedChunks` table for an unpacked version (populated by `ChunkIngressService`), and falls back to the packed chunk from the storage module. No on-the-fly unpacking — the server only returns unpacked if it was already cached. Wiring `Arc<ChunkProvider>` into `GossipDataHandler` is still needed. The `ChunkProvider` is already constructed in `chain.rs` and can be passed through `P2PService::run` into `GossipDataHandler::new`. `GossipDataHandler` is in `crates/p2p` and only needs the `ChunkStorageProvider` trait (from `irys-types`, which `p2p` already depends on).
## Cache Insertion: ChunkFormat to Bytes Conversion
The fetch returns a `ChunkFormat` — packed from the public API (always), or packed/unpacked from the gossip fallback (unpacked when the serving peer has it in MDBX cache). The `ChunkCache` stores `Arc<Bytes>` (raw unpacked chunk data), and the `ChunkDataIndex` DashMap maps `(u32, u64) → Arc<Bytes>`.
When a pulled chunk passes verification (local `data_root` derivation + `data_path` + leaf hash), PdService extracts the raw bytes for cache insertion:
```rust
// Unpack if packed; use directly if already unpacked (gossip cache hit)
let unpacked_bytes = match chunk_format {
ChunkFormat::Packed(packed) => {
irys_packing::unpack(&packed, &packing_config)?.bytes
}
ChunkFormat::Unpacked(chunk) => chunk.bytes,
};
let data: Arc<Bytes> = Arc::new(Bytes::from(unpacked_bytes));
// Insert with explicit reference per waiter (see on_fetch_done):
self.cache.insert(key, data.clone(), first_waiter_id);
for other_waiter in remaining_waiters {
self.cache.add_reference(key, other_waiter);
}
// cache.insert internally mirrors to the ChunkDataIndex DashMap
```
The `data_path`, `data_root`, and `data_size` are used only for verification and then discarded.
**TODO: When the public API endpoint is updated to also return unpacked chunks from MDBX cache (see Decision 6 TODO), the public API path will also benefit from skipping the unpack step.**
## Validation of Pulled Chunks
When PdService receives a `ChunkFormat` from a peer (packed from public API, packed or unpacked from gossip), it unpacks if needed, then verifies the chunk is authentic for the requested `(ledger, offset)` before inserting into the cache. Verification uses the requester's own canonical MDBX state — no server-supplied proof is needed.
**Verification pseudocode in `on_fetch_done`**:
```rust
// 0. Unpack if packed; use directly if already unpacked (gossip cache hit)
let (data_root, data_path, unpacked_bytes) = match chunk_format {
ChunkFormat::Packed(packed) => {
let unpacked = irys_packing::unpack(&packed, &packing_config)?;
(packed.data_root, packed.data_path, unpacked.bytes)
}
ChunkFormat::Unpacked(chunk) => {
(chunk.data_root, chunk.data_path, chunk.bytes)
}
};
// 1. Derive expected data_root locally from MDBX
let bounds = block_index.get_block_bounds(DataLedger::Publish, LedgerChunkOffset::from(key.offset))?;
let block_header = block_header_by_hash(&db_tx, &bounds.block_hash)?;
let tx_ids = block_header.get_data_ledger_tx_ids_ordered(DataLedger::Publish)?;
// Walk tx headers, accumulating chunk counts to find the tx containing key.offset
let mut running_offset = bounds.start_chunk_offset;
let mut expected_data_root = None;
for tx_id in tx_ids {
let tx_header = tx_header_by_txid(&db_tx, tx_id)?;
let num_chunks = tx_header.data_size.div_ceil(chunk_size);
if key.offset < running_offset + num_chunks {
expected_data_root = Some(tx_header.data_root);
break;
}
running_offset += num_chunks;
}
let expected_data_root = expected_data_root.ok_or("offset not found in block txs")?;
// 2. Verify chunk's data_root matches the locally derived expected value
ensure!(data_root == expected_data_root);
// 3. Verify data_path: expected_data_root → chunk bytes
let data_path_result = validate_path(expected_data_root.0, &data_path, chunk_end_byte)?;
ensure!(SHA256(unpacked_bytes) == data_path_result.leaf_hash);
```
If any verification step fails, the chunk is rejected, the peer is marked as having returned invalid data, and the fetch retries with a different peer.
**Batch optimization**: The `get_block_bounds` result and tx header lookups can be cached when fetching multiple chunks from the same block — the `data_root` resolution only needs to happen once per `DataTransaction` boundary.
## File Change Summary
| File | Change |
|---|---|
| `crates/types/src/gossip.rs` | Add `GossipDataRequestV2::PdChunk(u32, u64)` request variant, `GossipDataV2::PdChunk(ChunkFormat)` response variant, `to_v1()` returns `None` |
| `crates/types/src/chunk_provider.rs` | Add `get_chunk_for_pd` method to `ChunkStorageProvider` trait, returning `eyre::Result<Option<ChunkFormat>>` (checks MDBX cache for unpacked, falls back to packed from SM) |
| `crates/domain/src/models/chunk_provider.rs` | Implement `get_chunk_for_pd` on `ChunkProvider`: check MDBX `CachedChunks` for unpacked version first, fall back to packed from storage module. No on-the-fly unpacking. |
| `crates/api-server/src/routes/get_chunk.rs` | No changes (existing endpoint used as-is, always returns packed) |
| `crates/p2p/src/gossip_data_handler.rs` | Handle `PdChunk` in `resolve_data_request` using `get_chunk_for_pd`; add `storage_provider: Arc<dyn ChunkStorageProvider>` field |
| `crates/p2p/src/gossip_client.rs` | Add `pull_data_from_peers` method that accepts a pre-selected list of peer addresses (instead of using `top_active_peers`). Follows the same retry/handshake pattern as `pull_data_from_network` but with caller-supplied peers. |
| `crates/p2p/src/gossip_service.rs` | Pass `ChunkProvider` through to `GossipDataHandler` construction |
| `crates/actors/src/pd_service.rs` | Add `JoinSet`, `DelayQueue<RetryEntry>`, `pending_fetches`, `pending_blocks`, `own_miner_address`, new deps (`reqwest::Client`, `GossipClient`, `PeerList`, `BlockTreeReadGuard`, `BlockIndexReadGuard`, `DatabaseProvider`, `ConsensusConfig`). Refactor `handle_provision_chunks` and `handle_provision_block_chunks` to spawn fetch tasks on miss. Add `on_fetch_done` handler with local `data_root` derivation from MDBX, `irys_packing::unpack()`, `DelayQueue`-based retry logic. Add `on_retry_ready` handler. Add third and fourth `select!` arms for `join_set.join_next()` and `retry_queue.next()`. |
| `crates/actors/src/validation_service/block_validation_task.rs` | Add `CancellationToken` + `with_cancel` wrapper in `validate_block()` to cancel sibling tasks (including PD fetches) when any task fails definitively. No signature changes to individual validation functions. |
| `crates/actors/src/pd_service/provisioning.rs` | Add `PartiallyReady -> Ready` transition method callable from `on_fetch_done`. Extend `TxProvisioningState` or add helper for checking/clearing `missing_chunks`. |
| `crates/actors/src/pd_service/cache.rs` | No structural changes (insert/remove/reference tracking already work) |
| `crates/chain/src/chain.rs` | Pass `reqwest::Client`, `GossipClient`, `PeerList`, `BlockTreeReadGuard`, `BlockIndexReadGuard`, `DatabaseProvider`, `ConsensusConfig`, `own_miner_address` to `PdService::spawn_service` |
| `crates/chain-tests/src/programmable_data/pd_chunk_p2p_pull.rs` | **New file.** Integration tests for PD chunk P2P pull: happy path, multiple PD txs, chunk deduplication, mempool path. Shared `setup_pd_p2p_test()` helper. |
| `crates/chain-tests/src/programmable_data/mod.rs` | Add `mod pd_chunk_p2p_pull;` |
## Edge Cases
### Chunk needed by both mempool tx and block validation simultaneously
Handled by `pending_fetches` deduplication. A single `ChunkKey` entry tracks both `waiting_txs` and `waiting_blocks`. Only one fetch task is spawned. When the chunk arrives, both the tx's `missing_chunks` and the block's `remaining_keys` are updated.
### Oneshot receiver dropped before response sent
When block validation is cancelled, the oneshot receiver in `shadow_transactions_are_valid` is dropped. PdService detects this when it attempts `response.send(Ok(()))` — the `send` returns `Err`. PdService then cleans up: removes the `PendingBlockProvision` entry, decrements cache references for any chunks already fetched for that block, and removes the block hash from all `pending_fetches` entries. This mirrors the existing cleanup path in `handle_provision_block_chunks` when the oneshot fails (lines 352-363).
### All assigned peers fail to serve a chunk
The fetch task uses a **return-and-respawn** retry model with `DelayQueue`-based backoff. Each fetch task attempts all assigned peers once. If all fail, the task returns `Err(PdChunkFetchError::AllPeersFailed { excluded_peers })` to PdService via `join_set.join_next()`. The `on_fetch_done` handler then:
1. Checks whether waiters still exist for the chunk key — if not, cleans up and skips retry
2. Checks whether `MAX_CHUNK_FETCH_RETRIES` has been exceeded — if so, fails permanently
3. Computes backoff delay: `min(1s * 2^attempt, 30s)`
4. Inserts a `RetryEntry` into the actor-owned `DelayQueue` and transitions the fetch state to `FetchPhase::Backoff`
5. When the `DelayQueue` timer fires (via the `retry_queue.next()` select arm), `on_retry_ready` re-reads `resolve_peers_for_chunk` (picks up any epoch changes or peers coming online) and spawns a new fetch task into the JoinSet
This return-and-respawn model (vs. internal infinite retry within the task) ensures PdService can observe intermediate failures, update `FetchPhase`, and decide whether to continue retrying based on whether waiters still exist. If all waiters for a key have been removed (block cancelled, tx removed) between retry rounds, PdService simply skips the respawn. The `DelayQueue` approach avoids blocking the actor loop during backoff — retries are data in a queue, not sleeping tasks.
**Mempool tx retry bound**: For mempool transactions, retries continue until either the chunk is fetched or the transaction is removed from the Reth pool (which fires `TransactionRemoved` via `pd_transaction_monitor`). Reth's pool maintenance evicts transactions based on `max_queued_lifetime`, providing a natural upper bound. PdService does not need its own timeout for this path.
**Block validation retry bound**: For block validations, retries continue until the chunk arrives or the oneshot receiver is dropped (block validation cancelled by `exit_if_block_is_too_old`). PdService detects the dropped receiver when it checks `response.is_closed()` before spawning a retry.
The fetch task terminates after one pass through available peers:
- The chunk is successfully fetched → return `Ok(chunk)`
- All peers tried, all failed → return `Err(AllPeersFailed)`
- The task is aborted by JoinSet (PdService shutdown or explicit abort)
### Chunk arrives via gossip push while a pull is in-flight
If the codebase later adds push-based PD chunk gossip, a chunk could arrive via gossip and be written to storage while a pull fetch is in-flight for the same key. The pull fetch would return a duplicate chunk. PdService handles this gracefully: `cache.insert` for a key that already exists simply adds the reference without duplicating data (existing behavior at `cache.rs:85-91`).
### PdService message queue backpressure during fetch storms
PdService uses an unbounded channel (`mpsc::UnboundedSender`). A large number of `ProvisionBlockChunks` messages could queue up. However, this is the existing design and is bounded by the rate of block arrival. The JoinSet tasks run concurrently on the tokio runtime and do not block PdService's message processing — results are harvested via `join_next()` in the select loop.
### Duplicate ProvisionBlockChunks for the same block_hash
If two `ProvisionBlockChunks` messages arrive for the same `block_hash` (e.g., same block discovered via multiple gossip paths), the second message is rejected. Before storing the oneshot in `pending_blocks`, PdService checks if `pending_blocks.contains_key(&block_hash)`. If it does, the second oneshot is responded to with `Err` immediately — the first request is already in-flight and will complete. This prevents overwriting the first oneshot sender and losing it.
### Partition assignment changes during fetch
If the epoch transitions while fetch tasks are in-flight, the assigned miners for a partition may change. In-flight tasks continue with the stale peer list. If those peers no longer serve the data, the fetches fail and retry. On retry, `resolve_peers_for_chunk` reads the current epoch snapshot, getting the updated assignments. This is self-correcting.
## Observability
The PD chunk fetch path is latency-sensitive (blocks validation) and should be instrumented:
- **`pd_chunk_fetch_duration_ms`** — histogram of time from fetch task spawn to successful result, labeled by source (mempool vs. block_validation)
- **`pd_chunk_fetch_attempts`** — counter of fetch attempts, labeled by outcome (success, peer_not_found, peer_error, validation_failed)
- **`pd_chunk_fetch_retries`** — counter of retry respawns per chunk key
- **`pd_chunks_pending`** — gauge of currently in-flight fetch tasks (JoinSet size)
- **`pd_provision_cache_hit_rate`** — ratio of cache hits to total chunk lookups during provision
- **`pd_provision_local_storage_hit_rate`** — ratio of local storage hits to cache misses
- **`pd_tx_partially_ready_count`** — gauge of mempool txs in `PartiallyReady` state
- **`pd_block_provision_wait_ms`** — histogram of time a block validation waits on the oneshot (from `ProvisionBlockChunks` send to `Ok(())` response)
These follow the existing metrics patterns in the codebase (e.g., `record_gossip_chunk_processing_duration`, `record_gossip_chunk_received`).
## Integration Tests
### Test File
`crates/chain-tests/src/programmable_data/pd_chunk_p2p_pull.rs` — added to the existing PD test module (`mod.rs`).
### Shared Setup Helper
A reusable setup function that establishes the two-node topology used by all test cases:
```rust
struct PdP2pTestContext {
node_a: IrysNodeTest<Started>, // genesis, mining, has chunks
node_b: IrysNodeTest<Started>, // peer, validator-only, no local chunks
data_start_offset: u64, // global ledger offset of first uploaded chunk
partition_index: u64, // data_start_offset / num_chunks_in_partition
local_offset: u32, // data_start_offset % num_chunks_in_partition
num_chunks_uploaded: u16, // total chunks available for tests
chunk_size: u64, // bytes per chunk (32 in tests)
num_chunks_in_partition: u64, // partition size config
pd_signer: PrivateKeySigner, // funded account for PD tx submission
data_signer: PrivateKeySigner, // account used for data upload
}
/// Establishes the two-node topology and uploads real data on Node A.
async fn setup_pd_p2p_test() -> PdP2pTestContext { ... }
```
**Node A (genesis, miner, data holder)**:
- `IrysNodeTest::new_genesis(config)` with `NodeConfig::testing()` (Sprite hardfork active from genesis)
- Staked, pledged, mining-capable, with storage modules
- Small chunk size (32 bytes) for manageable test data
- `block_migration_depth` set low (e.g., 2) to speed up chunk migration
- `num_chunks_in_partition` set small (e.g., 10) for tractable partition layout — this controls how `resolve_peers_for_chunk` computes `slot_index = offset / num_chunks_in_partition`
**Data upload on Node A**:
- Post a publish data transaction with enough chunks to cover all test scenarios (e.g., 16 chunks × 32 bytes = 512 bytes)
- Upload unpacked chunks via HTTP `/v1/chunk` API
- Mine blocks until chunks migrate to storage modules (wait for `block_migration_depth` blocks past the data tx)
- Wait for `ChunkMigrationService` to write chunks to storage modules using the `wait_for_migrated_txs()` pattern followed by a brief sleep (e.g., 2 seconds) to account for async chunk migration writes — this follows the established pattern in `pd_content_verification.rs`
- Record `data_start_offset` from BlockIndex for constructing PD access lists
- Decompose into partition-relative coordinates for `ChunkRangeSpecifier` construction:
```rust
let partition_index = data_start_offset / num_chunks_in_partition;
let local_offset = (data_start_offset % num_chunks_in_partition) as u32;
```
**Node B (peer, validator-only, no local chunks)**:
- `IrysNodeTest::new(genesis.testing_peer_with_signer(&peer_signer))` — NOT staked, NOT pledged, NO storage modules, NOT mining
- Connected to Node A via trusted peers (gossip + API)
- P2P chunk fetch enabled (new PdService configuration)
- No data is uploaded to or packed on Node B — its `ChunkStorageProvider` naturally returns `Ok(None)` for all ledger offsets since no storage modules contain the relevant data
**No gossip authentication concern**: The primary fetch path uses the public HTTP API (`GET /v1/chunk/ledger/{id}/{offset}/pd`), which requires no authentication or staking. Node B (unstaked, validator-only) can fetch PD chunks from Node A's public API without any special gossip configuration. The gossip fallback path is not required for the integration tests.
**Sync gate**: Wait for Node B to sync to Node A's current tip using `wait_until_height_confirmed` (or equivalent migration-aware gate) — not just block tree tip sync. This ensures Node B's BlockIndex and DataTransactionHeaders are populated for the data-carrying block, which is required for local `data_root` derivation during chunk verification in `on_fetch_done`.
**Pre-test invariant**: Before each test's PD-specific logic, assert that Node B's `ChunkStorageProvider::get_unpacked_chunk_by_ledger_offset` returns `Ok(None)` for the test's target offsets. This proves the P2P fetch path is actually exercised — without this check, tests could pass vacuously if chunks were found locally.
### Test 1: Happy Path — Single PD Transaction Block Validation
**Topology**: Node A (genesis, mining, has chunks) → Node B (peer, validator-only, no chunks locally)
**Setup**: Call `setup_pd_p2p_test()`. Node A has migrated chunks at known ledger offsets.
**Test case**:
1. Assert pre-test invariant: Node B has no local chunks at target offsets
2. Construct a PD transaction referencing 2 chunks at known offsets (using `ChunkRangeSpecifier` with `partition_index` and `local_offset` from `PdP2pTestContext`)
3. Submit the PD tx to Node A's mempool
4. Node A mines a block including the PD tx (use `future_or_mine_on_timeout()` pattern)
5. Node B receives the block via gossip
6. Node B's PdService detects missing chunks during `handle_provision_block_chunks`
7. Node B fetches chunks from Node A via `GossipDataRequestV2::PdChunk`
8. Node B validates the block successfully (full proof chain: tx_path + data_path + leaf hash)
**Assertions**:
- Node B's canonical tip matches Node A's block hash (block validated and accepted)
- The PD tx is included in the validated block on Node B (check block body)
- Nodes remain in sync — no fork, no rejection
- Fetched chunks are present in Node B's `ChunkDataIndex` DashMap (the shared mirror the EVM precompile reads from)
### Test 2: Multiple PD Transactions in One Block
**Topology**: Node A (genesis, mining, has chunks) → Node B (peer, validator-only, no chunks locally)
**Setup**: Call `setup_pd_p2p_test()`. The uploaded data provides enough chunks for multiple non-overlapping ranges.
**Test case**:
1. Assert pre-test invariant: Node B has no local chunks at target offsets
2. Construct 3 PD transactions, each referencing different chunk ranges (partition-relative offsets from `local_offset`):
- TX1: offsets 0-1 (2 chunks)
- TX2: offsets 2-3 (2 chunks)
- TX3: offsets 4-5 (2 chunks)
3. Submit all 3 PD txs to Node A's mempool
4. Node A mines a block including all 3 PD txs
5. Node B receives and validates the block, fetching all 6 chunks from Node A via parallel fetch tasks
**Assertions**:
- Node B's canonical tip matches Node A's
- All 3 PD txs are in the validated block on Node B
- All 6 chunks are present in Node B's `ChunkDataIndex` DashMap
- Nodes remain in sync
### Test 3: Chunk Deduplication — Mempool TX and Block Validation Share a Fetch
**Topology**: Node A (genesis, mining, has chunks) → Node B (peer, validator-only, no chunks locally)
**Setup**: Call `setup_pd_p2p_test()`.
**Test case**:
1. Assert pre-test invariant: Node B has no local chunks at target offset X
2. Construct PD transaction T1 referencing chunk at offset X
3. Submit T1 directly to Node B's mempool (via Node B's RPC, not Node A)
4. T1 triggers `NewTransaction` in Node B → PdService detects missing chunks and starts fetching chunk X from Node A
5. Construct PD transaction T2 (different tx, same chunk at offset X) and submit to Node A's mempool
6. Node A mines a block containing T2
7. Node B receives the block → `ProvisionBlockChunks` for T2 either hits the cache (if fetch already completed) or joins the existing pending fetch as a second waiter
8. Both T1 (mempool waiter) and T2 (block waiter) are served
**Assertions**:
- Node B validates the block successfully (block waiter for T2 satisfied)
- T1 transitions to `Ready` in Node B's provisioning state (tx waiter for T1 satisfied)
- `ready_pd_txs` contains T1's tx hash
- Chunk X is present in Node B's `ChunkDataIndex` DashMap
**Timing note**: The relative timing of the fetch completion vs. block arrival matters. If the fetch completes before the block arrives, `ProvisionBlockChunks` hits the cache directly (cache hit path). If the block arrives while the fetch is still in-flight, the block's chunk key is added to `pending_fetches[X].waiting_blocks` (dedup path). Both outcomes are correct — the test asserts the end state regardless of which path executes.
### Test 4: Mempool Path — Fetch Chunks for Pending Transaction
**Topology**: Node A (genesis, mining, has chunks) → Node B (peer, validator-only, no chunks locally)
**Setup**: Call `setup_pd_p2p_test()`.
**Test case**:
1. Assert pre-test invariant: Node B has no local chunks at target offsets
2. Construct a PD transaction referencing 2-3 chunks at known offsets
3. Submit the PD tx directly to Node B's mempool (via Node B's RPC)
4. Node B's PdService detects missing chunks via `handle_provision_chunks`, marks the tx as `PartiallyReady`
5. PdService spawns fetch tasks into the JoinSet for each missing chunk
6. Fetch tasks pull chunks from Node A via `GossipDataRequestV2::PdChunk`
7. As each chunk arrives: proof chain verified, chunk inserted into cache, `missing_chunks` decremented
8. When last chunk arrives: tx transitions from `PartiallyReady` → `Ready`, tx_hash inserted into `ready_pd_txs`
**Assertions**:
- `ready_pd_txs` contains the tx hash (tx is available for block building)
- Fetched chunks are present in Node B's `ChunkDataIndex` DashMap
- The chunk bytes in `ChunkDataIndex` match the original data uploaded to Node A (byte-level verification)
### Future Test Scenarios
The following scenarios are valuable but out of scope for the initial implementation. They should be added as the implementation matures:
- **Retry after peer failure**: Node A's gossip temporarily disabled → Node B's fetch fails, retries with backoff via `DelayQueue`, eventually succeeds when gossip re-enabled. Exercises the `AllPeersFailed` → `on_retry_ready` path.
- **Block cancellation during fetch**: While Node B is fetching PD chunks, the tip advances past the block being validated → `exit_if_block_is_too_old` fires → fetch cancelled via `abort_handle.abort()`.
- **Sibling validation cancellation (CancellationToken)**: Another validation task fails (e.g., invalid PoA) while PD fetch is in-flight → `cancel.cancel()` fires → shadow_tx_task dropped → oneshot dropped → PdService cleanup.
- **Proof verification failure**: Serving peer returns a valid chunk from the wrong ledger position → tx_path verification fails → peer marked invalid, retry with different peer.
This one gets committed. It’s the artifact that matters — what you and your teammates review before any code gets written.
Phase 3: Implementation plan
Feed the design doc to another fresh session. This produces the concrete plan — specific file and line references, desired edits. The most prescriptive artifact.
Here’s one from a trading bot. Notice the specificity — file paths, exact code, test commands. The implementing agent doesn’t have to think about what to do, only how:
Example implementation plan: Inventory Manager view source ↗
# Inventory Manager — Implementation Plan
> **For Claude:** REQUIRED SUB-SKILL: Use superpowers:executing-plans to implement this plan task-by-task.
**Goal:** Build the `InventoryManager` — a single-owner component for capital and position state — running in parallel alongside the existing `ExecutionEngine` position tracking, with new `orders` and `mint_events` tables for durable in-flight tracking.
**Architecture:** The `InventoryManager` lives in `crates/execution/src/inventory.rs`. It owns an in-memory representation of USDC balances, token positions, and minted pairs, persisted via event sourcing through the `PersistenceLayer`. New `orders` and `mint_events` tables track in-flight operations for crash recovery. During this phase, both the existing `DashMap<PositionKey, PositionState>` and the new `InventoryManager` run side-by-side — discrepancies are logged but don't halt trading. The `DecisionContext` gains an optional `inventory: Option<InventoryState>` field populated every tick. Reconciliation against external APIs (CLOB, RPC) is deferred to Phase 2 of the overall arbitrage project when `CtfClient` exists; this plan covers fresh-session initialization and fill-replay-based position verification.
**Tech Stack:** Rust (rust_decimal, rusqlite, dashmap, uuid, chrono, serde), TypeScript (type declarations)
**Design doc:** `docs/plans/2026-03-08-arbitrage/02-inventory-manager.md`
---
## Task 1: Add InventoryState, TokenPosition, MintedPairBalance types
Add the three core inventory types to the shared types crate. These are `Clone + Serialize + Deserialize` value types passed to strategies via `DecisionContext`.
**Files:**
- Modify: `crates/types/src/lib.rs` (add after `PortfolioState` at line 347)
- Test: `crates/types/src/lib.rs` (add to existing `#[cfg(test)] mod tests`)
**Step 1: Add the Rust types**
Add after `PortfolioState` (line 347):
```rust
// ── Inventory types ─────────────────────────────────────────────────
/// Complete capital and position state for a session.
/// Passed to every strategy via DecisionContext on every tick.
/// This is a derived view — never persisted as a blob.
#[derive(Debug, Clone, PartialEq, Serialize, Deserialize)]
#[serde(rename_all = "camelCase")]
pub struct InventoryState {
/// Total USDC owned by this session.
pub total_usd: f64,
/// USDC committed to pending operations (open buy orders, pending mints).
pub in_flight_usd: f64,
/// Spendable USDC: total_usd - in_flight_usd.
pub accessible_usd: f64,
/// Per-token position state, keyed by token_id.
pub tokens: std::collections::HashMap<String, TokenPosition>,
/// Pre-minted YES+NO pairs, keyed by condition_id.
/// Empty for sessions that don't use mint/merge.
pub minted_pairs: std::collections::HashMap<String, MintedPairBalance>,
/// Whether exit has been triggered.
pub exit_triggered: bool,
}
/// Position state for a single token (YES or NO in a specific market).
#[derive(Debug, Clone, PartialEq, Serialize, Deserialize)]
#[serde(rename_all = "camelCase")]
pub struct TokenPosition {
pub token_id: String,
pub market_id: String,
pub outcome: Outcome,
pub qty: u64,
pub in_flight_qty: u64,
pub accessible_qty: u64,
#[serde(with = "rust_decimal::serde::float")]
pub avg_entry_price: Decimal,
pub total_cost: f64,
pub current_price: f64,
pub unrealized_pnl: f64,
#[serde(with = "rust_decimal::serde::float")]
pub realized_pnl: Decimal,
}
/// Minted YES+NO pair balance for a single condition (market).
#[derive(Debug, Clone, PartialEq, Serialize, Deserialize)]
#[serde(rename_all = "camelCase")]
pub struct MintedPairBalance {
pub condition_id: String,
pub available: u64,
pub reserved: u64,
pub total_minted: u64,
pub total_sold: u64,
pub total_merged: u64,
}
```
**Step 2: Write serde tests**
Add to the existing `#[cfg(test)] mod tests` block:
```rust
#[test]
fn inventory_state_serde_roundtrip() {
let state = InventoryState {
total_usd: 1000.0,
in_flight_usd: 65.0,
accessible_usd: 935.0,
tokens: std::collections::HashMap::new(),
minted_pairs: std::collections::HashMap::new(),
exit_triggered: false,
};
let json = serde_json::to_string(&state).unwrap();
assert!(json.contains(r#""totalUsd":1000"#), "camelCase: {json}");
assert!(json.contains(r#""inFlightUsd":65"#), "camelCase: {json}");
assert!(json.contains(r#""exitTriggered":false"#), "camelCase: {json}");
let rt: InventoryState = serde_json::from_str(&json).unwrap();
assert_eq!(state, rt);
}
#[test]
fn token_position_serde_roundtrip() {
let pos = TokenPosition {
token_id: "tok-1".into(),
market_id: "mkt-1".into(),
outcome: Outcome::Yes,
qty: 100,
in_flight_qty: 20,
accessible_qty: 80,
avg_entry_price: Decimal::new(65, 2), // 0.65
total_cost: 65.0,
current_price: 0.70,
unrealized_pnl: 5.0,
realized_pnl: Decimal::ZERO,
};
let json = serde_json::to_string(&pos).unwrap();
assert!(json.contains(r#""tokenId":"tok-1""#), "camelCase: {json}");
assert!(json.contains(r#""inFlightQty":20"#), "camelCase: {json}");
assert!(json.contains(r#""accessibleQty":80"#), "camelCase: {json}");
let rt: TokenPosition = serde_json::from_str(&json).unwrap();
assert_eq!(pos, rt);
}
#[test]
fn minted_pair_balance_serde_roundtrip() {
let pair = MintedPairBalance {
condition_id: "cond-1".into(),
available: 50,
reserved: 10,
total_minted: 100,
total_sold: 30,
total_merged: 10,
};
let json = serde_json::to_string(&pair).unwrap();
assert!(json.contains(r#""conditionId":"cond-1""#), "camelCase: {json}");
assert!(json.contains(r#""totalMinted":100"#), "camelCase: {json}");
let rt: MintedPairBalance = serde_json::from_str(&json).unwrap();
assert_eq!(pair, rt);
}
```
**Step 3: Run tests**
Run: `cargo test -p weatherman-types`
Expected: all existing tests pass + 3 new tests pass.
**Step 4: Commit**
```
feat(types): add InventoryState, TokenPosition, MintedPairBalance types
```
---
## Task 2: Add inventory field to DecisionContext
Add an optional `inventory` field to `DecisionContext`. Existing strategies see `undefined` in JS — backwards compatible.
**Files:**
- Modify: `crates/types/src/lib.rs:229-240` (DecisionContext struct)
- Test: `crates/types/src/lib.rs` (existing tests)
**Step 1: Add the field**
In the `DecisionContext` struct (line 231), add after the `portfolio` field:
```rust
#[serde(default, skip_serializing_if = "Option::is_none")]
pub inventory: Option<InventoryState>,
```
**Step 2: Fix all DecisionContext construction sites**
Search the codebase for where `DecisionContext` is constructed and add `inventory: None` to each. Key locations:
- `crates/weatherman/src/session.rs` (weather tick and book update branches)
- Any test files constructing DecisionContext
**Step 3: Write test**
```rust
#[test]
fn decision_context_inventory_omitted_when_none() {
let ctx = DecisionContext {
trigger: Trigger::BookUpdate,
tick_number: 1,
timestamp: chrono::Utc::now(),
session_id: "s1".into(),
weather: /* minimal WeatherState */ ,
markets: vec![],
positions: vec![],
portfolio: /* minimal PortfolioState */ ,
inventory: None,
};
let json = serde_json::to_string(&ctx).unwrap();
assert!(!json.contains("inventory"), "inventory should be omitted when None: {json}");
}
```
Note: Use the same test helper patterns as existing DecisionContext serde tests. If no minimal constructors exist, create a helper function.
**Step 4: Run tests**
Run: `cargo test -p weatherman-types && cargo test -p weatherman`
Expected: all pass. Compilation requires updating construction sites.
**Step 5: Commit**
```
feat(types): add optional inventory field to DecisionContext
```
---
## Task 3: Add orders and mint_events tables
Add the two new tables to the SQLite schema. These track in-flight operations for crash recovery.
**Files:**
- Modify: `crates/persistence/src/sqlite/schema.rs:76-87` (add after `markets` table, before closing `";`)
- Test: `crates/persistence/src/sqlite/schema.rs` (extend existing tests)
**Step 1: Write the failing test**
Add to the existing `mod tests` in schema.rs:
```rust
#[test]
fn test_initialize_creates_orders_and_mint_events_tables() {
let conn = Connection::open_in_memory().unwrap();
initialize(&conn).unwrap();
let tables: Vec<String> = conn
.prepare("SELECT name FROM sqlite_master WHERE type='table' ORDER BY name")
.unwrap()
.query_map([], |row| row.get(0))
.unwrap()
.filter_map(|r| r.ok())
.collect();
assert!(tables.contains(&"orders".to_string()));
assert!(tables.contains(&"mint_events".to_string()));
}
#[test]
fn test_orders_table_constraints() {
let conn = Connection::open_in_memory().unwrap();
initialize(&conn).unwrap();
// Insert a session first (FK constraint)
conn.execute(
"INSERT INTO sessions (id, mode, strategy_id, config_json, started_at) VALUES ('s1', 'paper', 'strat', '{}', '2026-01-01T00:00:00Z')",
[],
).unwrap();
// Valid insert
conn.execute(
"INSERT INTO orders (local_id, session_id, market_id, token_id, side, qty, limit_px, tif, reserved_usd, submitted_at, updated_at) VALUES ('ord-1', 's1', 'mkt-1', 'tok-1', 'buy', 100, 65, 'GTC', 6500, '2026-01-01T00:00:00Z', '2026-01-01T00:00:00Z')",
[],
).unwrap();
// Duplicate local_id should fail
let dup = conn.execute(
"INSERT INTO orders (local_id, session_id, market_id, token_id, side, qty, limit_px, tif, reserved_usd, submitted_at, updated_at) VALUES ('ord-1', 's1', 'mkt-1', 'tok-1', 'buy', 100, 65, 'GTC', 6500, '2026-01-01T00:00:00Z', '2026-01-01T00:00:00Z')",
[],
);
assert!(dup.is_err());
// Invalid side should fail
let bad_side = conn.execute(
"INSERT INTO orders (local_id, session_id, market_id, token_id, side, qty, limit_px, tif, reserved_usd, submitted_at, updated_at) VALUES ('ord-2', 's1', 'mkt-1', 'tok-1', 'hold', 100, 65, 'GTC', 6500, '2026-01-01T00:00:00Z', '2026-01-01T00:00:00Z')",
[],
);
assert!(bad_side.is_err());
}
#[test]
fn test_mint_events_table_constraints() {
let conn = Connection::open_in_memory().unwrap();
initialize(&conn).unwrap();
conn.execute(
"INSERT INTO sessions (id, mode, strategy_id, config_json, started_at) VALUES ('s1', 'paper', 'strat', '{}', '2026-01-01T00:00:00Z')",
[],
).unwrap();
// Valid insert with NULL tx_hash (crash before broadcast)
conn.execute(
"INSERT INTO mint_events (session_id, condition_id, operation, amount, submitted_at) VALUES ('s1', 'cond-1', 'MINT', 50000, '2026-01-01T00:00:00Z')",
[],
).unwrap();
// Valid insert with tx_hash
conn.execute(
"INSERT INTO mint_events (tx_hash, session_id, condition_id, operation, amount, submitted_at) VALUES ('0xabc', 's1', 'cond-1', 'MERGE', 25000, '2026-01-01T00:00:00Z')",
[],
).unwrap();
// Invalid operation should fail
let bad_op = conn.execute(
"INSERT INTO mint_events (session_id, condition_id, operation, amount, submitted_at) VALUES ('s1', 'cond-1', 'BURN', 50000, '2026-01-01T00:00:00Z')",
[],
);
assert!(bad_op.is_err());
}
```
**Step 2: Run test to verify it fails**
Run: `cargo test -p weatherman-persistence -- test_initialize_creates_orders`
Expected: FAIL (tables don't exist yet)
**Step 3: Add the DDL**
In `schema.rs`, inside the `execute_batch` string, add after the `markets` table (before the closing `";`):
```sql
CREATE TABLE IF NOT EXISTS orders (
local_id TEXT PRIMARY KEY,
exchange_order_id TEXT UNIQUE,
session_id TEXT NOT NULL REFERENCES sessions(id),
market_id TEXT NOT NULL,
token_id TEXT NOT NULL,
side TEXT NOT NULL CHECK(side IN ('buy', 'sell')),
qty INTEGER NOT NULL CHECK(qty > 0),
limit_px INTEGER NOT NULL CHECK(limit_px > 0 AND limit_px <= 100),
tif TEXT NOT NULL CHECK(tif IN ('GTC', 'GTD', 'FOK')),
group_id TEXT,
status TEXT NOT NULL DEFAULT 'SUBMITTED'
CHECK(status IN ('SUBMITTED', 'PARTIALLY_FILLED', 'FILLED', 'CANCELLED', 'EXPIRED')),
filled_qty INTEGER NOT NULL DEFAULT 0 CHECK(filled_qty >= 0),
reserved_usd INTEGER NOT NULL DEFAULT 0 CHECK(reserved_usd >= 0),
reserved_qty INTEGER NOT NULL DEFAULT 0 CHECK(reserved_qty >= 0),
submitted_at TEXT NOT NULL,
updated_at TEXT NOT NULL
);
CREATE INDEX IF NOT EXISTS idx_orders_session ON orders(session_id, status);
CREATE INDEX IF NOT EXISTS idx_orders_market ON orders(market_id, status);
CREATE INDEX IF NOT EXISTS idx_orders_exchange ON orders(exchange_order_id) WHERE exchange_order_id IS NOT NULL;
CREATE TABLE IF NOT EXISTS mint_events (
id INTEGER PRIMARY KEY AUTOINCREMENT,
tx_hash TEXT UNIQUE,
session_id TEXT NOT NULL REFERENCES sessions(id),
condition_id TEXT NOT NULL,
operation TEXT NOT NULL CHECK(operation IN ('MINT', 'MERGE')),
amount INTEGER NOT NULL CHECK(amount > 0),
status TEXT NOT NULL DEFAULT 'PENDING'
CHECK(status IN ('PENDING', 'CONFIRMED', 'FAILED')),
gas_cost INTEGER NOT NULL DEFAULT 0 CHECK(gas_cost >= 0),
submitted_at TEXT NOT NULL,
confirmed_at TEXT
);
CREATE INDEX IF NOT EXISTS idx_mint_session ON mint_events(session_id, status);
CREATE INDEX IF NOT EXISTS idx_mint_tx ON mint_events(tx_hash) WHERE tx_hash IS NOT NULL;
```
**Step 4: Update existing table test**
Add `"orders"` and `"mint_events"` to the assertion in `test_initialize_creates_all_tables`.
**Step 5: Run tests**
Run: `cargo test -p weatherman-persistence -- schema`
Expected: all pass.
**Step 6: Commit**
```
feat(persistence): add orders and mint_events tables for in-flight tracking
```
---
## Task 4: Add order DB operations
Add CRUD operations for the `orders` table.
**Files:**
- Modify: `crates/persistence/src/sqlite/ops.rs` (add functions after `insert_market`)
- Modify: `crates/persistence/src/layer.rs` (add PersistenceLayer wrappers)
- Test: `crates/persistence/src/sqlite/ops.rs` (add to existing test module)
**Step 1: Write tests**
Add to `ops.rs` test module:
```rust
#[test]
fn test_insert_order() {
let conn = setup();
let now = Utc::now();
insert_session(&conn, "sess-1", "paper", "strat-v1", "{}", &now).unwrap();
insert_order(
&conn, "ord-1", "sess-1", "mkt-1", "tok-1", "buy", 100, 65, "GTC",
None, 6500, 0, &now,
).unwrap();
let (status, qty, reserved): (String, i64, i64) = conn
.query_row(
"SELECT status, qty, reserved_usd FROM orders WHERE local_id = ?1",
["ord-1"],
|row| Ok((row.get(0)?, row.get(1)?, row.get(2)?)),
).unwrap();
assert_eq!(status, "SUBMITTED");
assert_eq!(qty, 100);
assert_eq!(reserved, 6500);
}
#[test]
fn test_update_order_exchange_id() {
let conn = setup();
let now = Utc::now();
insert_session(&conn, "sess-1", "paper", "strat-v1", "{}", &now).unwrap();
insert_order(
&conn, "ord-1", "sess-1", "mkt-1", "tok-1", "buy", 100, 65, "GTC",
None, 6500, 0, &now,
).unwrap();
update_order_exchange_id(&conn, "ord-1", "exch-abc").unwrap();
let eid: Option<String> = conn
.query_row(
"SELECT exchange_order_id FROM orders WHERE local_id = ?1",
["ord-1"],
|row| row.get(0),
).unwrap();
assert_eq!(eid.as_deref(), Some("exch-abc"));
}
#[test]
fn test_update_order_fill() {
let conn = setup();
let now = Utc::now();
insert_session(&conn, "sess-1", "paper", "strat-v1", "{}", &now).unwrap();
insert_order(
&conn, "ord-1", "sess-1", "mkt-1", "tok-1", "buy", 100, 65, "GTC",
None, 6500, 0, &now,
).unwrap();
// Partial fill
update_order_fill(&conn, "ord-1", 50, "PARTIALLY_FILLED", &now).unwrap();
let (filled, status): (i64, String) = conn
.query_row(
"SELECT filled_qty, status FROM orders WHERE local_id = ?1",
["ord-1"],
|row| Ok((row.get(0)?, row.get(1)?)),
).unwrap();
assert_eq!(filled, 50);
assert_eq!(status, "PARTIALLY_FILLED");
// Full fill
update_order_fill(&conn, "ord-1", 100, "FILLED", &now).unwrap();
let (filled, status): (i64, String) = conn
.query_row(
"SELECT filled_qty, status FROM orders WHERE local_id = ?1",
["ord-1"],
|row| Ok((row.get(0)?, row.get(1)?)),
).unwrap();
assert_eq!(filled, 100);
assert_eq!(status, "FILLED");
}
#[test]
fn test_update_order_status() {
let conn = setup();
let now = Utc::now();
insert_session(&conn, "sess-1", "paper", "strat-v1", "{}", &now).unwrap();
insert_order(
&conn, "ord-1", "sess-1", "mkt-1", "tok-1", "buy", 100, 65, "GTC",
None, 6500, 0, &now,
).unwrap();
update_order_status(&conn, "ord-1", "CANCELLED", &now).unwrap();
let status: String = conn
.query_row(
"SELECT status FROM orders WHERE local_id = ?1",
["ord-1"],
|row| row.get(0),
).unwrap();
assert_eq!(status, "CANCELLED");
}
#[test]
fn test_load_inflight_orders() {
let conn = setup();
let now = Utc::now();
insert_session(&conn, "sess-1", "paper", "strat-v1", "{}", &now).unwrap();
insert_order(&conn, "o1", "sess-1", "mkt-1", "t1", "buy", 100, 65, "GTC", None, 6500, 0, &now).unwrap();
insert_order(&conn, "o2", "sess-1", "mkt-1", "t1", "sell", 50, 70, "FOK", None, 0, 50, &now).unwrap();
insert_order(&conn, "o3", "sess-1", "mkt-1", "t1", "buy", 200, 60, "GTC", None, 12000, 0, &now).unwrap();
update_order_status(&conn, "o3", "FILLED", &now).unwrap();
let orders = load_inflight_orders(&conn, "sess-1").unwrap();
assert_eq!(orders.len(), 2); // o1 and o2 (o3 is FILLED)
}
```
**Step 2: Run tests to verify they fail**
Run: `cargo test -p weatherman-persistence -- test_insert_order`
Expected: FAIL (function doesn't exist)
**Step 3: Implement the operations**
Add to `ops.rs`:
```rust
pub fn insert_order(
conn: &Connection,
local_id: &str,
session_id: &str,
market_id: &str,
token_id: &str,
side: &str,
qty: i64,
limit_px: i64,
tif: &str,
group_id: Option<&str>,
reserved_usd: i64,
reserved_qty: i64,
submitted_at: &DateTime<Utc>,
) -> Result<(), PersistenceError> {
let now = submitted_at.to_rfc3339();
conn.execute(
"INSERT INTO orders (local_id, session_id, market_id, token_id, side, qty, limit_px, tif, group_id, reserved_usd, reserved_qty, submitted_at, updated_at) VALUES (?1, ?2, ?3, ?4, ?5, ?6, ?7, ?8, ?9, ?10, ?11, ?12, ?13)",
rusqlite::params![local_id, session_id, market_id, token_id, side, qty, limit_px, tif, group_id, reserved_usd, reserved_qty, now, now],
)?;
Ok(())
}
pub fn update_order_exchange_id(
conn: &Connection,
local_id: &str,
exchange_order_id: &str,
) -> Result<(), PersistenceError> {
conn.execute(
"UPDATE orders SET exchange_order_id = ?1 WHERE local_id = ?2",
rusqlite::params![exchange_order_id, local_id],
)?;
Ok(())
}
pub fn update_order_fill(
conn: &Connection,
local_id: &str,
filled_qty: i64,
status: &str,
updated_at: &DateTime<Utc>,
) -> Result<(), PersistenceError> {
conn.execute(
"UPDATE orders SET filled_qty = ?1, status = ?2, updated_at = ?3 WHERE local_id = ?4",
rusqlite::params![filled_qty, status, updated_at.to_rfc3339(), local_id],
)?;
Ok(())
}
pub fn update_order_status(
conn: &Connection,
local_id: &str,
status: &str,
updated_at: &DateTime<Utc>,
) -> Result<(), PersistenceError> {
conn.execute(
"UPDATE orders SET status = ?1, updated_at = ?2 WHERE local_id = ?3",
rusqlite::params![status, updated_at.to_rfc3339(), local_id],
)?;
Ok(())
}
/// Row returned by load_inflight_orders.
pub struct OrderRow {
pub local_id: String,
pub exchange_order_id: Option<String>,
pub market_id: String,
pub token_id: String,
pub side: String,
pub qty: i64,
pub limit_px: i64,
pub tif: String,
pub group_id: Option<String>,
pub status: String,
pub filled_qty: i64,
pub reserved_usd: i64,
pub reserved_qty: i64,
}
pub fn load_inflight_orders(
conn: &Connection,
session_id: &str,
) -> Result<Vec<OrderRow>, PersistenceError> {
let mut stmt = conn.prepare(
"SELECT local_id, exchange_order_id, market_id, token_id, side, qty, limit_px, tif, group_id, status, filled_qty, reserved_usd, reserved_qty FROM orders WHERE session_id = ?1 AND status IN ('SUBMITTED', 'PARTIALLY_FILLED')"
)?;
let rows = stmt.query_map(rusqlite::params![session_id], |row| {
Ok(OrderRow {
local_id: row.get(0)?,
exchange_order_id: row.get(1)?,
market_id: row.get(2)?,
token_id: row.get(3)?,
side: row.get(4)?,
qty: row.get(5)?,
limit_px: row.get(6)?,
tif: row.get(7)?,
group_id: row.get(8)?,
status: row.get(9)?,
filled_qty: row.get(10)?,
reserved_usd: row.get(11)?,
reserved_qty: row.get(12)?,
})
})?;
rows.collect::<Result<Vec<_>, _>>().map_err(PersistenceError::from)
}
```
**Step 4: Add PersistenceLayer wrappers**
Add to `layer.rs` after the existing `insert_market` method:
```rust
pub fn insert_order(
&self,
local_id: &str, session_id: &str, market_id: &str, token_id: &str,
side: &str, qty: i64, limit_px: i64, tif: &str, group_id: Option<&str>,
reserved_usd: i64, reserved_qty: i64, submitted_at: &DateTime<Utc>,
) -> Result<(), PersistenceError> {
let conn = self.db.lock().unwrap();
ops::insert_order(&conn, local_id, session_id, market_id, token_id, side, qty, limit_px, tif, group_id, reserved_usd, reserved_qty, submitted_at)
}
pub fn update_order_exchange_id(&self, local_id: &str, exchange_order_id: &str) -> Result<(), PersistenceError> {
let conn = self.db.lock().unwrap();
ops::update_order_exchange_id(&conn, local_id, exchange_order_id)
}
pub fn update_order_fill(&self, local_id: &str, filled_qty: i64, status: &str, updated_at: &DateTime<Utc>) -> Result<(), PersistenceError> {
let conn = self.db.lock().unwrap();
ops::update_order_fill(&conn, local_id, filled_qty, status, updated_at)
}
pub fn update_order_status(&self, local_id: &str, status: &str, updated_at: &DateTime<Utc>) -> Result<(), PersistenceError> {
let conn = self.db.lock().unwrap();
ops::update_order_status(&conn, local_id, status, updated_at)
}
pub fn load_inflight_orders(&self, session_id: &str) -> Result<Vec<ops::OrderRow>, PersistenceError> {
let conn = self.db.lock().unwrap();
ops::load_inflight_orders(&conn, session_id)
}
```
**Step 5: Run tests**
Run: `cargo test -p weatherman-persistence`
Expected: all pass.
**Step 6: Commit**
```
feat(persistence): add order CRUD operations for in-flight tracking
```
---
## Task 5: Add mint_events DB operations
Add CRUD operations for the `mint_events` table.
**Files:**
- Modify: `crates/persistence/src/sqlite/ops.rs`
- Modify: `crates/persistence/src/layer.rs`
- Test: `crates/persistence/src/sqlite/ops.rs`
**Step 1: Write tests**
```rust
#[test]
fn test_insert_mint_event() {
let conn = setup();
let now = Utc::now();
insert_session(&conn, "sess-1", "paper", "strat-v1", "{}", &now).unwrap();
insert_mint_event(&conn, Some("0xabc"), "sess-1", "cond-1", "MINT", 50000, &now).unwrap();
let (status, amount): (String, i64) = conn
.query_row(
"SELECT status, amount FROM mint_events WHERE tx_hash = ?1",
["0xabc"],
|row| Ok((row.get(0)?, row.get(1)?)),
).unwrap();
assert_eq!(status, "PENDING");
assert_eq!(amount, 50000);
}
#[test]
fn test_insert_mint_event_null_tx_hash() {
let conn = setup();
let now = Utc::now();
insert_session(&conn, "sess-1", "paper", "strat-v1", "{}", &now).unwrap();
// Crash before broadcast — tx_hash is NULL
let id = insert_mint_event(&conn, None, "sess-1", "cond-1", "MINT", 50000, &now).unwrap();
assert!(id > 0);
}
#[test]
fn test_update_mint_event_status() {
let conn = setup();
let now = Utc::now();
insert_session(&conn, "sess-1", "paper", "strat-v1", "{}", &now).unwrap();
insert_mint_event(&conn, Some("0xabc"), "sess-1", "cond-1", "MINT", 50000, &now).unwrap();
update_mint_event_status(&conn, "0xabc", "CONFIRMED", 1500000, Some(&now)).unwrap();
let (status, gas, confirmed): (String, i64, Option<String>) = conn
.query_row(
"SELECT status, gas_cost, confirmed_at FROM mint_events WHERE tx_hash = ?1",
["0xabc"],
|row| Ok((row.get(0)?, row.get(1)?, row.get(2)?)),
).unwrap();
assert_eq!(status, "CONFIRMED");
assert_eq!(gas, 1500000);
assert!(confirmed.is_some());
}
#[test]
fn test_load_pending_mints() {
let conn = setup();
let now = Utc::now();
insert_session(&conn, "sess-1", "paper", "strat-v1", "{}", &now).unwrap();
insert_mint_event(&conn, Some("0xabc"), "sess-1", "cond-1", "MINT", 50000, &now).unwrap();
insert_mint_event(&conn, Some("0xdef"), "sess-1", "cond-1", "MERGE", 25000, &now).unwrap();
insert_mint_event(&conn, Some("0x123"), "sess-1", "cond-2", "MINT", 30000, &now).unwrap();
update_mint_event_status(&conn, "0x123", "CONFIRMED", 0, Some(&now)).unwrap();
let pending = load_pending_mints(&conn, "sess-1").unwrap();
assert_eq!(pending.len(), 2); // 0xabc and 0xdef (0x123 is CONFIRMED)
}
```
**Step 2: Run tests to verify failure**
Run: `cargo test -p weatherman-persistence -- test_insert_mint_event`
Expected: FAIL
**Step 3: Implement**
Add to `ops.rs`:
```rust
/// Insert a mint/merge event. Returns the auto-generated row ID.
pub fn insert_mint_event(
conn: &Connection,
tx_hash: Option<&str>,
session_id: &str,
condition_id: &str,
operation: &str,
amount: i64,
submitted_at: &DateTime<Utc>,
) -> Result<i64, PersistenceError> {
conn.execute(
"INSERT INTO mint_events (tx_hash, session_id, condition_id, operation, amount, submitted_at) VALUES (?1, ?2, ?3, ?4, ?5, ?6)",
rusqlite::params![tx_hash, session_id, condition_id, operation, amount, submitted_at.to_rfc3339()],
)?;
Ok(conn.last_insert_rowid())
}
pub fn update_mint_event_status(
conn: &Connection,
tx_hash: &str,
status: &str,
gas_cost: i64,
confirmed_at: Option<&DateTime<Utc>>,
) -> Result<(), PersistenceError> {
conn.execute(
"UPDATE mint_events SET status = ?1, gas_cost = ?2, confirmed_at = ?3 WHERE tx_hash = ?4",
rusqlite::params![status, gas_cost, confirmed_at.map(|t| t.to_rfc3339()), tx_hash],
)?;
Ok(())
}
pub struct MintEventRow {
pub id: i64,
pub tx_hash: Option<String>,
pub condition_id: String,
pub operation: String,
pub amount: i64,
pub status: String,
}
pub fn load_pending_mints(
conn: &Connection,
session_id: &str,
) -> Result<Vec<MintEventRow>, PersistenceError> {
let mut stmt = conn.prepare(
"SELECT id, tx_hash, condition_id, operation, amount, status FROM mint_events WHERE session_id = ?1 AND status = 'PENDING'"
)?;
let rows = stmt.query_map(rusqlite::params![session_id], |row| {
Ok(MintEventRow {
id: row.get(0)?,
tx_hash: row.get(1)?,
condition_id: row.get(2)?,
operation: row.get(3)?,
amount: row.get(4)?,
status: row.get(5)?,
})
})?;
rows.collect::<Result<Vec<_>, _>>().map_err(PersistenceError::from)
}
```
**Step 4: Add PersistenceLayer wrappers**
Same pattern as Task 4 — delegate to `ops::` functions with `self.db.lock().unwrap()`.
**Step 5: Run tests**
Run: `cargo test -p weatherman-persistence`
Expected: all pass.
**Step 6: Commit**
```
feat(persistence): add mint_events CRUD operations
```
---
## Task 6: Atomic fill + position persistence
Wrap `insert_fill` + `upsert_position` in a single SQLite transaction. This prevents the case where a crash between the two leaves the position cache stale.
**Files:**
- Modify: `crates/persistence/src/sqlite/ops.rs`
- Modify: `crates/persistence/src/layer.rs`
- Test: `crates/persistence/src/sqlite/ops.rs`
**Step 1: Write test**
```rust
#[test]
fn test_insert_fill_and_position_atomic() {
let conn = setup();
let now = Utc::now();
insert_session(&conn, "sess-1", "paper", "strat-v1", "{}", &now).unwrap();
insert_fill_and_position(
&conn,
// fill params
"fill-1", "ord-1", "sess-1", "mkt-1", "tok-1", "buy", 100, 6500, 50, &now,
// position params
"mkt-1", "tok-1", "sess-1", "buy", 100, 6500, 0, 0, &now,
).unwrap();
// Both should exist
let fill_count: i64 = conn
.query_row("SELECT COUNT(*) FROM fills WHERE fill_id = 'fill-1'", [], |row| row.get(0))
.unwrap();
let pos_qty: i64 = conn
.query_row(
"SELECT qty FROM positions WHERE market_id = 'mkt-1' AND token_id = 'tok-1' AND session_id = 'sess-1'",
[], |row| row.get(0),
).unwrap();
assert_eq!(fill_count, 1);
assert_eq!(pos_qty, 100);
}
#[test]
fn test_insert_fill_and_position_duplicate_fill_is_idempotent() {
let conn = setup();
let now = Utc::now();
insert_session(&conn, "sess-1", "paper", "strat-v1", "{}", &now).unwrap();
insert_fill_and_position(
&conn,
"fill-1", "ord-1", "sess-1", "mkt-1", "tok-1", "buy", 100, 6500, 50, &now,
"mkt-1", "tok-1", "sess-1", "buy", 100, 6500, 0, 0, &now,
).unwrap();
// Second call with same fill_id should be idempotent (INSERT OR IGNORE)
let result = insert_fill_and_position(
&conn,
"fill-1", "ord-1", "sess-1", "mkt-1", "tok-1", "buy", 100, 6500, 50, &now,
"mkt-1", "tok-1", "sess-1", "buy", 200, 6600, 0, 0, &now,
);
// Should either succeed (ignore dup fill, still upsert position) or error on fill uniqueness.
// We choose: fail on duplicate fill_id to detect replay bugs explicitly.
assert!(result.is_err());
}
```
**Step 2: Implement**
Add to `ops.rs`:
```rust
/// Atomically insert a fill and upsert the position in a single transaction.
/// Fails on duplicate fill_id (UNIQUE constraint) — caller should dedup.
pub fn insert_fill_and_position(
conn: &Connection,
// fill params
fill_id: &str, order_id: &str, session_id: &str,
fill_market_id: &str, fill_token_id: &str, fill_side: &str,
fill_qty: i64, fill_price: i64, fill_fee: i64, fill_timestamp: &DateTime<Utc>,
// position params
pos_market_id: &str, pos_token_id: &str, pos_session_id: &str,
pos_side: &str, pos_qty: i64, pos_avg_price: i64,
pos_realized_pnl: i64, pos_unrealized_pnl: i64, pos_updated_at: &DateTime<Utc>,
) -> Result<(), PersistenceError> {
let tx = conn.unchecked_transaction()?;
tx.execute(
"INSERT INTO fills (fill_id, order_id, session_id, market_id, token_id, side, qty, price, fee, timestamp) VALUES (?1, ?2, ?3, ?4, ?5, ?6, ?7, ?8, ?9, ?10)",
rusqlite::params![fill_id, order_id, session_id, fill_market_id, fill_token_id, fill_side, fill_qty, fill_price, fill_fee, fill_timestamp.to_rfc3339()],
)?;
tx.execute(
"INSERT INTO positions (market_id, token_id, session_id, side, qty, avg_price, realized_pnl, unrealized_pnl, updated_at)
VALUES (?1, ?2, ?3, ?4, ?5, ?6, ?7, ?8, ?9)
ON CONFLICT(market_id, token_id, session_id) DO UPDATE SET
side = excluded.side, qty = excluded.qty, avg_price = excluded.avg_price,
realized_pnl = excluded.realized_pnl, unrealized_pnl = excluded.unrealized_pnl,
updated_at = excluded.updated_at",
rusqlite::params![pos_market_id, pos_token_id, pos_session_id, pos_side, pos_qty, pos_avg_price, pos_realized_pnl, pos_unrealized_pnl, pos_updated_at.to_rfc3339()],
)?;
tx.commit()?;
Ok(())
}
```
Note: Uses `unchecked_transaction()` because we have `&Connection` not `&mut Connection` (the mutex gives us exclusive access). This is the same pattern SQLite uses when WAL mode guarantees single-writer semantics.
**Step 3: Add PersistenceLayer wrapper**
```rust
pub fn insert_fill_and_position(
&self,
fill_id: &str, order_id: &str, session_id: &str,
fill_market_id: &str, fill_token_id: &str, fill_side: &str,
fill_qty: i64, fill_price: i64, fill_fee: i64, fill_timestamp: &DateTime<Utc>,
pos_market_id: &str, pos_token_id: &str, pos_session_id: &str,
pos_side: &str, pos_qty: i64, pos_avg_price: i64,
pos_realized_pnl: i64, pos_unrealized_pnl: i64, pos_updated_at: &DateTime<Utc>,
) -> Result<(), PersistenceError> {
let conn = self.db.lock().unwrap();
ops::insert_fill_and_position(
&conn,
fill_id, order_id, session_id, fill_market_id, fill_token_id, fill_side,
fill_qty, fill_price, fill_fee, fill_timestamp,
pos_market_id, pos_token_id, pos_session_id,
pos_side, pos_qty, pos_avg_price, pos_realized_pnl, pos_unrealized_pnl, pos_updated_at,
)
}
```
**Step 4: Run tests**
Run: `cargo test -p weatherman-persistence`
Expected: all pass.
**Step 5: Commit**
```
feat(persistence): add atomic fill + position transaction
```
---
## Task 7: Update TypeScript type declarations
Add inventory types to the TypeScript declarations so strategies get IDE support.
**Files:**
- Modify: `strategies/lib/types.d.ts`
**Step 1: Add interfaces**
Add after `PortfolioState` interface (after line 94):
```typescript
interface InventoryState {
/** Total USDC owned by this session. */
totalUsd: number;
/** USDC committed to pending operations. */
inFlightUsd: number;
/** Spendable USDC (totalUsd - inFlightUsd). */
accessibleUsd: number;
/** Per-token position state, keyed by tokenId. */
tokens: Record<string, TokenPositionState>;
/** Minted YES+NO pairs, keyed by conditionId. Empty if no minting. */
mintedPairs: Record<string, MintedPairBalance>;
/** Whether exit has been triggered. */
exitTriggered: boolean;
}
interface TokenPositionState {
tokenId: string;
marketId: string;
outcome: "YES" | "NO";
qty: number;
inFlightQty: number;
accessibleQty: number;
avgEntryPrice: number;
totalCost: number;
currentPrice: number;
unrealizedPnl: number;
realizedPnl: number;
}
interface MintedPairBalance {
conditionId: string;
available: number;
reserved: number;
totalMinted: number;
totalSold: number;
totalMerged: number;
}
```
**Step 2: Add inventory to DecisionContext**
Update the `DecisionContext` interface to include the optional field:
```typescript
interface DecisionContext {
trigger: Trigger;
tickNumber: number;
timestamp: string;
sessionId: string;
weather: WeatherState;
markets: MarketState[];
positions: PositionState[];
portfolio: PortfolioState;
/** Inventory state. Present when InventoryManager is active. */
inventory?: InventoryState;
}
```
**Step 3: Commit**
```
feat(types): add InventoryState TypeScript declarations
```
---
## Task 8: Create InventoryManager with core state management
Create the `InventoryManager` struct and its initialization/snapshot logic.
**Files:**
- Create: `crates/execution/src/inventory.rs`
- Modify: `crates/execution/src/lib.rs` (add `pub mod inventory;`)
- Modify: `crates/execution/Cargo.toml` (add `rusqlite` dep if not present)
- Test: `crates/execution/src/inventory.rs`
**Step 1: Write tests for core functionality**
```rust
#[cfg(test)]
mod tests {
use super::*;
use rust_decimal_macros::dec;
fn make_manager(initial_capital_usd: f64) -> InventoryManager {
InventoryManager::new(initial_capital_usd)
}
#[test]
fn fresh_manager_has_full_capital_accessible() {
let mgr = make_manager(1000.0);
let snap = mgr.snapshot();
assert_eq!(snap.total_usd, 1000.0);
assert_eq!(snap.in_flight_usd, 0.0);
assert_eq!(snap.accessible_usd, 1000.0);
assert!(snap.tokens.is_empty());
assert!(snap.minted_pairs.is_empty());
assert!(!snap.exit_triggered);
}
#[test]
fn can_buy_within_budget() {
let mgr = make_manager(1000.0);
// 100 contracts at $0.65 = $65
assert!(mgr.can_buy(100, 65));
// 2000 contracts at $0.65 = $1300 > $1000
assert!(!mgr.can_buy(2000, 65));
}
#[test]
fn can_sell_with_no_position() {
let mgr = make_manager(1000.0);
assert!(!mgr.can_sell("tok-1", 10));
}
#[test]
fn can_mint_within_budget() {
let mgr = make_manager(1000.0);
assert!(mgr.can_mint(500.0));
assert!(!mgr.can_mint(1500.0));
}
}
```
**Step 2: Implement InventoryManager struct**
Create `crates/execution/src/inventory.rs`:
```rust
use std::collections::HashMap;
use rust_decimal::Decimal;
use rust_decimal::prelude::ToPrimitive;
use weatherman_types::{InventoryState, MintedPairBalance, Outcome, TokenPosition};
use crate::convert::centibps_to_decimal;
/// Internal position state tracked by the InventoryManager.
/// Richer than the snapshot type — includes Decimal precision fields.
#[derive(Debug, Clone)]
struct InternalPosition {
token_id: String,
market_id: String,
outcome: Outcome,
qty: u64,
in_flight_qty: u64,
avg_entry_price: Decimal,
total_cost: Decimal,
current_price: Decimal,
realized_pnl: Decimal,
}
/// The InventoryManager is the single authority for capital and position state.
/// It takes `&mut self` — not thread-safe by design. Runs within the session's
/// sequential tick loop.
pub struct InventoryManager {
/// Total USDC owned by this session.
total_usd: Decimal,
/// USDC committed to in-flight buy orders and pending mints.
in_flight_usd: Decimal,
/// Per-token positions, keyed by token_id.
positions: HashMap<String, InternalPosition>,
/// Minted pair balances, keyed by condition_id.
minted_pairs: HashMap<String, MintedPairBalance>,
/// Whether exit has been triggered.
exit_triggered: bool,
}
impl InventoryManager {
/// Create a fresh InventoryManager for a new session.
pub fn new(initial_capital_usd: f64) -> Self {
Self {
total_usd: Decimal::try_from(initial_capital_usd).unwrap_or(Decimal::ZERO),
in_flight_usd: Decimal::ZERO,
positions: HashMap::new(),
minted_pairs: HashMap::new(),
exit_triggered: false,
}
}
/// Build an immutable InventoryState snapshot for the strategy.
pub fn snapshot(&self) -> InventoryState {
let accessible = self.total_usd - self.in_flight_usd;
let tokens: HashMap<String, TokenPosition> = self.positions.iter().map(|(id, p)| {
let accessible_qty = p.qty.saturating_sub(p.in_flight_qty);
let unrealized_pnl = if p.qty > 0 {
(p.current_price - p.avg_entry_price) * Decimal::from(p.qty)
} else {
Decimal::ZERO
};
(id.clone(), TokenPosition {
token_id: p.token_id.clone(),
market_id: p.market_id.clone(),
outcome: p.outcome,
qty: p.qty,
in_flight_qty: p.in_flight_qty,
accessible_qty,
avg_entry_price: p.avg_entry_price,
total_cost: p.total_cost.to_f64().unwrap_or(0.0),
current_price: p.current_price.to_f64().unwrap_or(0.0),
unrealized_pnl: unrealized_pnl.to_f64().unwrap_or(0.0),
realized_pnl: p.realized_pnl,
})
}).collect();
InventoryState {
total_usd: self.total_usd.to_f64().unwrap_or(0.0),
in_flight_usd: self.in_flight_usd.to_f64().unwrap_or(0.0),
accessible_usd: accessible.to_f64().unwrap_or(0.0),
tokens,
minted_pairs: self.minted_pairs.clone(),
exit_triggered: self.exit_triggered,
}
}
/// Update current prices for all positions from live book data.
/// `prices` maps token_id → mid_price as centibps (0-100).
pub fn update_prices(&mut self, prices: &HashMap<String, u64>) {
for (token_id, pos) in &mut self.positions {
if let Some(&mid_centibps) = prices.get(token_id) {
pos.current_price = centibps_to_decimal(mid_centibps);
}
}
}
/// Set exit triggered.
pub fn trigger_exit(&mut self) {
self.exit_triggered = true;
}
// ── Risk checks ────────────────────────────────────────────
/// Check if a buy order can be funded.
/// cost = qty * limit_px centibps-dollars, converted to USD.
pub fn can_buy(&self, qty: u64, limit_px: u64) -> bool {
let cost = Decimal::from(qty) * Decimal::from(limit_px) / Decimal::from(100u64);
let accessible = self.total_usd - self.in_flight_usd;
accessible >= cost
}
/// Check if a sell order can be filled from inventory.
pub fn can_sell(&self, token_id: &str, qty: u64) -> bool {
self.positions
.get(token_id)
.map_or(false, |p| p.qty.saturating_sub(p.in_flight_qty) >= qty)
}
/// Check if a mint can be funded.
pub fn can_mint(&self, amount_usd: f64) -> bool {
let amount = Decimal::try_from(amount_usd).unwrap_or(Decimal::MAX);
let accessible = self.total_usd - self.in_flight_usd;
accessible >= amount
}
}
```
**Step 3: Register the module**
In `crates/execution/src/lib.rs`, add:
```rust
pub mod inventory;
```
And add to the pub use block:
```rust
pub use inventory::InventoryManager;
```
**Step 4: Run tests**
Run: `cargo test -p weatherman-execution -- inventory`
Expected: all pass.
**Step 5: Commit**
```
feat(execution): add InventoryManager with core state and risk checks
```
---
## Task 9: InventoryManager order lifecycle handlers
Add methods for order submission, acceptance, fill, and cancellation.
**Files:**
- Modify: `crates/execution/src/inventory.rs`
**Step 1: Write tests**
```rust
#[test]
fn order_submitted_reserves_usd_for_buy() {
let mut mgr = make_manager(1000.0);
// Buy 100 at $0.65 = $65 reserved
mgr.on_order_submitted_buy("ord-1", "mkt-1", "tok-1", Outcome::Yes, 100, 65);
let snap = mgr.snapshot();
assert_eq!(snap.in_flight_usd, 65.0);
assert_eq!(snap.accessible_usd, 935.0);
}
#[test]
fn order_submitted_reserves_qty_for_sell() {
let mut mgr = make_manager(1000.0);
// Manually add a position first
mgr.add_position("tok-1", "mkt-1", Outcome::Yes, 100, dec!(0.65));
mgr.on_order_submitted_sell("ord-1", "tok-1", 50);
let snap = mgr.snapshot();
let pos = snap.tokens.get("tok-1").unwrap();
assert_eq!(pos.in_flight_qty, 50);
assert_eq!(pos.accessible_qty, 50);
}
#[test]
fn fill_buy_updates_position_and_releases_reserve() {
let mut mgr = make_manager(1000.0);
mgr.on_order_submitted_buy("ord-1", "mkt-1", "tok-1", Outcome::Yes, 100, 65);
// Full fill at $0.65
mgr.on_fill_buy("ord-1", "tok-1", "mkt-1", Outcome::Yes, 100, dec!(0.65), 100);
let snap = mgr.snapshot();
assert_eq!(snap.in_flight_usd, 0.0);
let pos = snap.tokens.get("tok-1").unwrap();
assert_eq!(pos.qty, 100);
assert!((pos.avg_entry_price - dec!(0.65)).abs() < dec!(0.001));
}
#[test]
fn fill_sell_realizes_pnl() {
let mut mgr = make_manager(1000.0);
mgr.add_position("tok-1", "mkt-1", Outcome::Yes, 100, dec!(0.65));
mgr.on_order_submitted_sell("ord-1", "tok-1", 50);
// Sell 50 at $0.75 → realized PnL = (0.75 - 0.65) * 50 = $5.00
mgr.on_fill_sell("ord-1", "tok-1", 50, dec!(0.75), 50);
let snap = mgr.snapshot();
let pos = snap.tokens.get("tok-1").unwrap();
assert_eq!(pos.qty, 50);
assert!((pos.realized_pnl - dec!(5.0)).abs() < dec!(0.01));
}
#[test]
fn order_cancelled_releases_reserve() {
let mut mgr = make_manager(1000.0);
mgr.on_order_submitted_buy("ord-1", "mkt-1", "tok-1", Outcome::Yes, 100, 65);
assert_eq!(mgr.snapshot().in_flight_usd, 65.0);
mgr.on_order_cancelled_buy("ord-1", 100, 65);
assert_eq!(mgr.snapshot().in_flight_usd, 0.0);
assert_eq!(mgr.snapshot().accessible_usd, 1000.0);
}
#[test]
fn partial_fill_then_cancel_releases_remainder() {
let mut mgr = make_manager(1000.0);
mgr.on_order_submitted_buy("ord-1", "mkt-1", "tok-1", Outcome::Yes, 100, 65);
// Partial fill: 60 of 100
mgr.on_fill_buy("ord-1", "tok-1", "mkt-1", Outcome::Yes, 60, dec!(0.65), 100);
let snap = mgr.snapshot();
// Released: 60 * 65 / 100 = $39, remaining in-flight: $26
assert!((snap.in_flight_usd - 26.0).abs() < 0.01);
// Cancel remainder
mgr.on_order_cancelled_buy("ord-1", 40, 65);
assert!((mgr.snapshot().in_flight_usd).abs() < 0.01);
}
#[test]
fn vwap_across_multiple_fills() {
let mut mgr = make_manager(1000.0);
mgr.on_order_submitted_buy("o1", "mkt-1", "tok-1", Outcome::Yes, 100, 60);
mgr.on_fill_buy("o1", "tok-1", "mkt-1", Outcome::Yes, 100, dec!(0.60), 100);
mgr.on_order_submitted_buy("o2", "mkt-1", "tok-1", Outcome::Yes, 100, 70);
mgr.on_fill_buy("o2", "tok-1", "mkt-1", Outcome::Yes, 100, dec!(0.70), 100);
let snap = mgr.snapshot();
let pos = snap.tokens.get("tok-1").unwrap();
assert_eq!(pos.qty, 200);
// VWAP: (100*0.60 + 100*0.70) / 200 = 0.65
assert!((pos.avg_entry_price - dec!(0.65)).abs() < dec!(0.001));
}
```
**Step 2: Implement order lifecycle methods**
Add to `InventoryManager` impl block:
```rust
// ── Internal helpers (for testing) ─────────────────────────
/// Add a position directly (for testing and recovery).
#[cfg(test)]
pub fn add_position(&mut self, token_id: &str, market_id: &str, outcome: Outcome, qty: u64, avg_price: Decimal) {
let total_cost = avg_price * Decimal::from(qty);
self.positions.insert(token_id.to_string(), InternalPosition {
token_id: token_id.to_string(),
market_id: market_id.to_string(),
outcome,
qty,
in_flight_qty: 0,
avg_entry_price: avg_price,
total_cost,
current_price: avg_price,
realized_pnl: Decimal::ZERO,
});
}
// ── Order event handlers ───────────────────────────────────
/// Record a buy order submission. Reserves USDC.
pub fn on_order_submitted_buy(
&mut self, _local_id: &str, _market_id: &str, _token_id: &str,
_outcome: Outcome, qty: u64, limit_px: u64,
) {
let reserved = Decimal::from(qty) * Decimal::from(limit_px) / Decimal::from(100u64);
self.in_flight_usd += reserved;
}
/// Record a sell order submission. Reserves token quantity.
pub fn on_order_submitted_sell(&mut self, _local_id: &str, token_id: &str, qty: u64) {
if let Some(pos) = self.positions.get_mut(token_id) {
pos.in_flight_qty += qty;
}
}
/// Record a buy fill. Updates position with VWAP, releases proportional reserve.
pub fn on_fill_buy(
&mut self, _local_id: &str, token_id: &str, market_id: &str,
outcome: Outcome, fill_qty: u64, fill_price: Decimal, order_qty: u64,
) {
// Update position (VWAP)
let pos = self.positions.entry(token_id.to_string()).or_insert_with(|| {
InternalPosition {
token_id: token_id.to_string(),
market_id: market_id.to_string(),
outcome,
qty: 0,
in_flight_qty: 0,
avg_entry_price: Decimal::ZERO,
total_cost: Decimal::ZERO,
current_price: Decimal::ZERO,
realized_pnl: Decimal::ZERO,
}
});
let old_qty = Decimal::from(pos.qty);
let new_qty = old_qty + Decimal::from(fill_qty);
pos.avg_entry_price = if new_qty.is_zero() {
Decimal::ZERO
} else {
(pos.avg_entry_price * old_qty + fill_price * Decimal::from(fill_qty)) / new_qty
};
pos.qty += fill_qty;
pos.total_cost = pos.avg_entry_price * Decimal::from(pos.qty);
// Debit capital
let cost = fill_price * Decimal::from(fill_qty);
self.total_usd -= cost;
// Release proportional in-flight reserve
// The order reserved (order_qty * limit_px / 100). We release fill_qty's share.
// But we don't know the original limit_px here — we release based on actual cost.
// Simpler: release the cost of the fill from in_flight.
self.in_flight_usd = (self.in_flight_usd - cost).max(Decimal::ZERO);
}
/// Record a sell fill. Realizes PnL, releases token reserve.
pub fn on_fill_sell(
&mut self, _local_id: &str, token_id: &str, fill_qty: u64,
fill_price: Decimal, _order_qty: u64,
) {
if let Some(pos) = self.positions.get_mut(token_id) {
let sell_qty = std::cmp::min(fill_qty, pos.qty);
let realized = (fill_price - pos.avg_entry_price) * Decimal::from(sell_qty);
pos.realized_pnl += realized;
pos.qty -= sell_qty;
pos.in_flight_qty = pos.in_flight_qty.saturating_sub(fill_qty);
// Credit capital
let proceeds = fill_price * Decimal::from(sell_qty);
self.total_usd += proceeds;
if pos.qty == 0 {
pos.avg_entry_price = Decimal::ZERO;
pos.total_cost = Decimal::ZERO;
} else {
pos.total_cost = pos.avg_entry_price * Decimal::from(pos.qty);
}
}
}
/// Cancel/reject a buy order. Releases the remaining reserved USDC.
pub fn on_order_cancelled_buy(&mut self, _local_id: &str, remaining_qty: u64, limit_px: u64) {
let released = Decimal::from(remaining_qty) * Decimal::from(limit_px) / Decimal::from(100u64);
self.in_flight_usd = (self.in_flight_usd - released).max(Decimal::ZERO);
}
/// Cancel/reject a sell order. Releases the remaining reserved quantity.
pub fn on_order_cancelled_sell(&mut self, _local_id: &str, token_id: &str, remaining_qty: u64) {
if let Some(pos) = self.positions.get_mut(token_id) {
pos.in_flight_qty = pos.in_flight_qty.saturating_sub(remaining_qty);
}
}
```
Note: The `_local_id` parameters are accepted but unused in the in-memory logic — they're needed for the DB persistence path that the session integration (Task 12) will wire up.
**Step 3: Run tests**
Run: `cargo test -p weatherman-execution -- inventory`
Expected: all pass.
**Step 4: Commit**
```
feat(execution): add InventoryManager order lifecycle handlers
```
---
## Task 10: InventoryManager mint/merge lifecycle handlers
Add methods for mint/merge submission, confirmation, and failure.
**Files:**
- Modify: `crates/execution/src/inventory.rs`
**Step 1: Write tests**
```rust
#[test]
fn mint_submitted_reserves_usd() {
let mut mgr = make_manager(1000.0);
mgr.on_mint_submitted("cond-1", 500.0);
let snap = mgr.snapshot();
assert_eq!(snap.in_flight_usd, 500.0);
assert_eq!(snap.accessible_usd, 500.0);
}
#[test]
fn mint_confirmed_creates_positions_and_pairs() {
let mut mgr = make_manager(1000.0);
mgr.on_mint_submitted("cond-1", 500.0);
// Mint creates 500 YES+NO pairs (each at $0.50 cost basis)
mgr.on_mint_confirmed("cond-1", 500, "tok-yes", "tok-no", "mkt-1");
let snap = mgr.snapshot();
assert_eq!(snap.in_flight_usd, 0.0);
// total_usd should be reduced by mint cost
assert!((snap.total_usd - 500.0).abs() < 0.01);
let pair = snap.minted_pairs.get("cond-1").unwrap();
assert_eq!(pair.available, 500);
assert_eq!(pair.total_minted, 500);
// YES and NO positions created at $0.50 each
let yes = snap.tokens.get("tok-yes").unwrap();
assert_eq!(yes.qty, 500);
assert!((yes.avg_entry_price - dec!(0.50)).abs() < dec!(0.01));
let no = snap.tokens.get("tok-no").unwrap();
assert_eq!(no.qty, 500);
}
#[test]
fn mint_failed_releases_reserve() {
let mut mgr = make_manager(1000.0);
mgr.on_mint_submitted("cond-1", 500.0);
mgr.on_mint_failed("cond-1", 500.0);
let snap = mgr.snapshot();
assert_eq!(snap.in_flight_usd, 0.0);
assert_eq!(snap.total_usd, 1000.0);
}
#[test]
fn merge_confirmed_credits_usd_and_removes_pairs() {
let mut mgr = make_manager(1000.0);
// Setup: mint first
mgr.on_mint_submitted("cond-1", 500.0);
mgr.on_mint_confirmed("cond-1", 500, "tok-yes", "tok-no", "mkt-1");
// Merge 200 pairs back to USDC
mgr.on_merge_submitted("cond-1", 200);
let snap = mgr.snapshot();
let pair = snap.minted_pairs.get("cond-1").unwrap();
assert_eq!(pair.available, 300); // 500 - 200 reserved
assert_eq!(pair.reserved, 200);
mgr.on_merge_confirmed("cond-1", 200, "tok-yes", "tok-no");
let snap = mgr.snapshot();
let pair = snap.minted_pairs.get("cond-1").unwrap();
assert_eq!(pair.available, 300);
assert_eq!(pair.reserved, 0);
assert_eq!(pair.total_merged, 200);
// YES and NO positions reduced
let yes = snap.tokens.get("tok-yes").unwrap();
assert_eq!(yes.qty, 300);
}
```
**Step 2: Implement mint/merge handlers**
Add to `InventoryManager` impl:
```rust
// ── Mint/Merge event handlers ──────────────────────────────
/// Record a mint submission. Reserves USDC.
pub fn on_mint_submitted(&mut self, _condition_id: &str, amount_usd: f64) {
let amount = Decimal::try_from(amount_usd).unwrap_or(Decimal::ZERO);
self.in_flight_usd += amount;
}
/// Record a mint confirmation. Creates YES+NO positions and minted pair balance.
pub fn on_mint_confirmed(
&mut self, condition_id: &str, pair_count: u64,
yes_token_id: &str, no_token_id: &str, market_id: &str,
) {
let amount = Decimal::from(pair_count) * Decimal::from(100u64) / Decimal::from(100u64);
// Each pair costs $1.00 (YES + NO = $1), so pair_count pairs = pair_count USD
// But from the caller's perspective, `amount_usd` was reserved at submission.
// Release the in-flight reserve.
let mint_cost = Decimal::from(pair_count);
self.in_flight_usd = (self.in_flight_usd - mint_cost).max(Decimal::ZERO);
self.total_usd -= mint_cost;
// Create/update YES position at $0.50 cost basis
let half = Decimal::new(5, 1); // 0.50
for (token_id, outcome) in [
(yes_token_id, Outcome::Yes),
(no_token_id, Outcome::No),
] {
let pos = self.positions.entry(token_id.to_string()).or_insert_with(|| {
InternalPosition {
token_id: token_id.to_string(),
market_id: market_id.to_string(),
outcome,
qty: 0,
in_flight_qty: 0,
avg_entry_price: Decimal::ZERO,
total_cost: Decimal::ZERO,
current_price: half,
realized_pnl: Decimal::ZERO,
}
});
let old_qty = Decimal::from(pos.qty);
let new_qty = old_qty + Decimal::from(pair_count);
pos.avg_entry_price = if new_qty.is_zero() {
Decimal::ZERO
} else {
(pos.avg_entry_price * old_qty + half * Decimal::from(pair_count)) / new_qty
};
pos.qty += pair_count;
pos.total_cost = pos.avg_entry_price * Decimal::from(pos.qty);
}
// Update minted pair balance
let pair = self.minted_pairs.entry(condition_id.to_string()).or_insert_with(|| {
MintedPairBalance {
condition_id: condition_id.to_string(),
available: 0,
reserved: 0,
total_minted: 0,
total_sold: 0,
total_merged: 0,
}
});
pair.available += pair_count;
pair.total_minted += pair_count;
}
/// Record a mint failure. Release reserved USDC.
pub fn on_mint_failed(&mut self, _condition_id: &str, amount_usd: f64) {
let amount = Decimal::try_from(amount_usd).unwrap_or(Decimal::ZERO);
self.in_flight_usd = (self.in_flight_usd - amount).max(Decimal::ZERO);
}
/// Record a merge submission. Reserves minted pairs.
pub fn on_merge_submitted(&mut self, condition_id: &str, pair_count: u64) {
if let Some(pair) = self.minted_pairs.get_mut(condition_id) {
let reserve = std::cmp::min(pair_count, pair.available);
pair.available -= reserve;
pair.reserved += reserve;
}
}
/// Record a merge confirmation. Credits USDC, removes pairs and token positions.
pub fn on_merge_confirmed(
&mut self, condition_id: &str, pair_count: u64,
yes_token_id: &str, no_token_id: &str,
) {
// Credit USDC
self.total_usd += Decimal::from(pair_count);
// Update pair balance
if let Some(pair) = self.minted_pairs.get_mut(condition_id) {
pair.reserved = pair.reserved.saturating_sub(pair_count);
pair.total_merged += pair_count;
}
// Reduce token positions
for token_id in [yes_token_id, no_token_id] {
if let Some(pos) = self.positions.get_mut(token_id) {
pos.qty = pos.qty.saturating_sub(pair_count);
if pos.qty == 0 {
pos.avg_entry_price = Decimal::ZERO;
pos.total_cost = Decimal::ZERO;
} else {
pos.total_cost = pos.avg_entry_price * Decimal::from(pos.qty);
}
}
}
}
/// Record a merge failure. Unreserve pairs.
pub fn on_merge_failed(&mut self, condition_id: &str, pair_count: u64) {
if let Some(pair) = self.minted_pairs.get_mut(condition_id) {
let unreserve = std::cmp::min(pair_count, pair.reserved);
pair.reserved -= unreserve;
pair.available += unreserve;
}
}
```
**Step 3: Run tests**
Run: `cargo test -p weatherman-execution -- inventory`
Expected: all pass.
**Step 4: Commit**
```
feat(execution): add InventoryManager mint/merge lifecycle handlers
```
---
## Task 11: Load positions from DB for recovery
Add a method to initialize `InventoryManager` state from persisted positions (the "fast-start cache"). This handles session resume without full reconciliation.
**Files:**
- Modify: `crates/persistence/src/sqlite/ops.rs` (add `load_positions`)
- Modify: `crates/persistence/src/layer.rs` (add wrapper)
- Modify: `crates/execution/src/inventory.rs` (add `load_positions`)
**Step 1: Write DB test**
```rust
#[test]
fn test_load_positions() {
let conn = setup();
let now = Utc::now();
insert_session(&conn, "sess-1", "paper", "strat-v1", "{}", &now).unwrap();
upsert_position(&conn, "mkt-1", "tok-1", "sess-1", "buy", 100, 6500, 300, 0, &now).unwrap();
upsert_position(&conn, "mkt-1", "tok-2", "sess-1", "buy", 50, 4000, 0, 100, &now).unwrap();
let positions = load_positions(&conn, "sess-1").unwrap();
assert_eq!(positions.len(), 2);
assert_eq!(positions[0].qty, 100);
}
```
**Step 2: Implement load_positions**
Add to `ops.rs`:
```rust
pub struct PositionRow {
pub market_id: String,
pub token_id: String,
pub side: String,
pub qty: i64,
pub avg_price: i64,
pub realized_pnl: i64,
pub unrealized_pnl: i64,
}
pub fn load_positions(
conn: &Connection,
session_id: &str,
) -> Result<Vec<PositionRow>, PersistenceError> {
let mut stmt = conn.prepare(
"SELECT market_id, token_id, side, qty, avg_price, realized_pnl, unrealized_pnl FROM positions WHERE session_id = ?1"
)?;
let rows = stmt.query_map(rusqlite::params![session_id], |row| {
Ok(PositionRow {
market_id: row.get(0)?,
token_id: row.get(1)?,
side: row.get(2)?,
qty: row.get(3)?,
avg_price: row.get(4)?,
realized_pnl: row.get(5)?,
unrealized_pnl: row.get(6)?,
})
})?;
rows.collect::<Result<Vec<_>, _>>().map_err(PersistenceError::from)
}
```
**Step 3: Add InventoryManager::load_positions method**
Add to `inventory.rs`:
```rust
/// Load positions from DB rows (fast-start cache on recovery).
/// token_id → outcome mapping must be provided by the caller (from MarketMeta).
pub fn load_positions(
&mut self,
rows: &[(String, String, String, u64, Decimal, Decimal)],
// (token_id, market_id, side_str, qty, avg_price, realized_pnl)
) {
for (token_id, market_id, _side, qty, avg_price, realized_pnl) in rows {
self.positions.insert(token_id.clone(), InternalPosition {
token_id: token_id.clone(),
market_id: market_id.clone(),
outcome: Outcome::Yes, // Caller resolves from MarketMeta
qty: *qty,
in_flight_qty: 0,
avg_entry_price: *avg_price,
total_cost: *avg_price * Decimal::from(*qty),
current_price: *avg_price, // Will be updated on first tick
realized_pnl: *realized_pnl,
});
}
}
```
**Step 4: Add PersistenceLayer wrapper and run tests**
Run: `cargo test -p weatherman-persistence -- test_load_positions && cargo test -p weatherman-execution -- inventory`
Expected: all pass.
**Step 5: Commit**
```
feat: add position loading for InventoryManager recovery
```
---
## Task 12: Wire InventoryManager into session (parallel system)
Integrate `InventoryManager` into the session tick loop so that `ctx.inventory` is populated on every tick, while the existing `DashMap` position tracking continues to run.
**Files:**
- Modify: `crates/weatherman/src/session.rs` (session initialization and tick loop)
- Modify: `crates/weatherman/src/providers.rs` (add to SessionDeps if needed)
**Step 1: Add InventoryManager to session state**
In `session.rs`, where session dependencies are set up (around line 376-404), create an `InventoryManager`:
```rust
use weatherman_execution::InventoryManager;
// After existing initialization, before tick loop:
let mut inventory_mgr = InventoryManager::new(session.initial_capital_usd);
```
**Step 2: Populate ctx.inventory on weather ticks**
In the weather timer branch (around lines 503-520), where `DecisionContext` is built, add:
```rust
// After building current_positions and portfolio:
// Update inventory prices from current book data
let price_map: HashMap<String, u64> = /* build from book data */;
inventory_mgr.update_prices(&price_map);
let ctx = DecisionContext {
trigger: Trigger::WeatherRefresh,
tick_number,
timestamp: chrono::Utc::now(),
session_id: session_id.clone(),
weather: weather_state,
markets: market_states,
positions: current_positions,
portfolio,
inventory: Some(inventory_mgr.snapshot()),
};
```
**Step 3: Populate ctx.inventory on book updates**
Same pattern in the book update branch (around lines 555-576).
**Step 4: Update InventoryManager on fills**
In `run_strategy_tick()` (around lines 231-294), after each fill is processed by the existing engine, also update the `InventoryManager`:
```rust
for fill in &batch_report.fills {
// Existing persistence logic stays...
// Also update InventoryManager (parallel tracking)
match fill.side {
Side::Buy => {
inventory_mgr.on_fill_buy(
&fill.order_id, &fill.token_id, &fill.market_id,
/* outcome from market meta */, fill.qty, fill.price, fill.qty,
);
}
Side::Sell => {
inventory_mgr.on_fill_sell(
&fill.order_id, &fill.token_id, fill.qty, fill.price, fill.qty,
);
}
}
}
```
**Step 5: Log discrepancies between old and new systems**
After building the snapshot, compare key fields:
```rust
// Compare old portfolio vs new inventory for discrepancy detection
if let Some(ref inv) = ctx.inventory {
let old_available = ctx.portfolio.available_capital_usd;
let new_accessible = inv.accessible_usd;
if (old_available - new_accessible).abs() > 1.0 {
tracing::warn!(
old_available, new_accessible,
"inventory/portfolio discrepancy detected"
);
}
}
```
**Step 6: Run tests**
Run: `cargo test -p weatherman`
Expected: existing session tests pass. `ctx.inventory` is now `Some(...)`.
**Step 7: Commit**
```
feat(session): wire InventoryManager as parallel tracking system
```
---
## Task 13: Persist orders via InventoryManager in fill path
Wire the order DB operations into the existing fill processing path so that order lifecycle is durably tracked.
**Files:**
- Modify: `crates/weatherman/src/session.rs` (run_strategy_tick)
**Step 1: Record order submissions before execution**
In `run_strategy_tick`, before `deps.engine.execute_batch(intents)`:
```rust
// Record each order intent in the orders table BEFORE execution
let mut local_ids: Vec<String> = Vec::new();
for intent in &intents {
if let Intent::Order(order) = intent {
let local_id = uuid::Uuid::new_v4().to_string();
let token_id = /* resolve from market meta */;
let (reserved_usd, reserved_qty) = match order.side {
Side::Buy => ((order.qty as i64) * (order.limit_px as i64), 0i64),
Side::Sell => (0i64, order.qty as i64),
};
deps.persistence.insert_order(
&local_id, &session_id, &order.market_id, &token_id,
&order.side.to_string(), order.qty as i64, order.limit_px as i64,
&format!("{:?}", order.tif), order.group_id.as_deref(),
reserved_usd, reserved_qty, &chrono::Utc::now(),
).ok(); // Log but don't halt on persistence failure
local_ids.push(local_id);
}
}
```
**Step 2: Update order status on fill**
After each fill, update the order status:
```rust
if let Some(local_id) = local_ids.get(idx) {
deps.persistence.update_order_fill(
local_id, fill.qty as i64, "FILLED", &chrono::Utc::now(),
).ok();
}
```
**Step 3: Run tests**
Run: `cargo test -p weatherman`
Expected: all pass.
**Step 4: Commit**
```
feat(session): persist order lifecycle to orders table
```
---
## Post-Implementation Notes
### What this plan builds
- `InventoryState`, `TokenPosition`, `MintedPairBalance` types (Rust + TypeScript)
- `orders` and `mint_events` DB tables with full CRUD
- Atomic fill + position persistence
- `InventoryManager` with order and mint/merge lifecycle tracking
- Position loading from DB for session recovery
- Parallel tracking wired into the session tick loop
### What is deferred
- **Full reconciliation against CLOB API and Polygon RPC** — requires `CtfClient` (Phase 2 of arbitrage project). The position-from-fills replay is implemented; external API reconciliation (steps 3-4 of the startup reconciliation in the design doc) is deferred.
- **Cutover from DashMap to InventoryManager** (Migration Phase 3 in design doc) — will be a separate plan after parallel validation confirms correctness.
- **Remove compatibility shim** (Migration Phase 4) — after cutover is stable.
- **PRAGMA synchronous = FULL for live mode** — will be added when live mode is activated.
### Verification approach
After implementation, run `cargo test --workspace` to verify all tests pass. Then run a paper trading session and inspect logs for any inventory/portfolio discrepancy warnings.
Phase 4: Implementation
Now and only now does code get written. Feed the plan to a fresh session (or subagents in a worktree). No guessing, no hallucinating architecture, no drift.
Phase 5: Review
AI reviews before any human sees it. CodeRabbit on CI (nitpicky but catches real stuff). Locally — agent teams with assigned roles + /codex second opinion. Here’s an actual review prompt I used:
The current PR adds new functionality for term ledgers. I want you to use agent teams with roles on security and correctness to review the feature branch - focus on mempool, gossip path, public api path, block validation. and dispatch /codex subcommand to get a second opinion. create a markdown file as an artifact. our main goal is to ensure that the changes to tx pricing work, that we properly compute term fee rewards on epoch block boundaries (and miners get rewarded), and that the rewards are also epoch-aware and use the correct pricing information when given out
I break the review approach down below.
Compact into artifacts, not into the void
The artifacts aren’t just “specs are good” — they’re your weapon against context degradation.
You can /compact and lose everything into the void. Or you can dump what the agent learned into a markdown file that a new agent can pick up.
The workflow:
- Work with Claude until context is getting bloated (remember the 40% rule from Part 2)
- Ask it to produce a markdown artifact capturing all current state
- Start a fresh session
- Feed the artifact to the new session as context
When you compact, make sure the artifact includes (h/t HumanLayer):
- End goal — what are we building and why
- Current approach — the plan we’re following
- Completed steps — what’s done, what passed
- Active blockers — what’s failing, what’s unclear
This is literally what the pipeline does — each phase produces an artifact that feeds the next with fresh context. The pipeline isn’t just about planning, it’s about context management.
War story: the Kotlin app I can’t read
War story: pagan rituals and the Flutter app
Years ago I built a Flutter app for a side project. Auth, websockets, Bluetooth Low Energy, locked-screen support — the works. It did not survive first contact with users.
Phones would overheat. JWT sessions wouldn’t refresh. WS connections had weird edge cases around bad signal. The users, unbeknownst to me, had created a whole ceremony akin to a pagan ritual.
They’d disable screen locking and put their phones in cases backwards to prevent accidental presses. When connection was lost — kill the app, turn off the phone for a minute, turn it back on. Just restarting the app didn’t work, ofc.
I did not have the desire nor the capacity to deal with it much further.
The spec-first rewrite (Christmas 2025)
Around Christmas of 2025 I decided to try throwing Claude at the problem. Here’s what I did — and this is the pipeline in action:
- I asked Claude to analyze the Rust backend that provided the ws communication protocol, create a spec for it (Phase 1 — research)
- Then I analyzed the behaviour of the Flutter app and created a spec from that as well (Phase 1 — more research)
- Then I used both specs to set up the Kotlin project structure and plan the scaffolding (Phase 2+3 — design + plan)
- Prompted it to implement, and iterated until it was feature complete (Phase 4)
The secret weapon here was adb — Claude could take screenshots of the phone screen via adb shell screencap, pull the image, look at the actual UI state, and iterate. Button looks off? It sees it. Navigation broke? It sees the error screen. This is the key insight: creating feedback loops within a session is everything. The AI needs a way to validate its own work. Without that loop you’re the feedback mechanism, and that doesn’t scale. With adb screenshots, Claude had eyes on the app and could self-correct without me describing what was wrong.
What do I mean by 'spec'?
When I say spec, I literally mean a markdown file with ascii diagrams, flows and descriptions. Something like:
## WebSocket Protocol
### Connection Flow
Client -> Server: AUTH {jwt_token}
Server -> Client: AUTH_OK {session_id}
Client -> Server: SUBSCRIBE {device_id}
...
### Message Types
- AUTH: Initial authentication handshake
- SUBSCRIBE: Register for device events
- HEARTBEAT: Keep-alive ping every 30s
...
### Error Handling
- On AUTH failure: server closes connection with code 4001
- On device disconnect: server sends DEVICE_LOST event
...This is the kind of artifact that gives an LLM everything it needs to implement correctly. The model doesn’t have to guess at the protocol, the edge cases, or the expected behaviour. It’s all right there.
Now, after completely vibe-coding the app, it is much more stable, prettier, and works without any bugs. The users love it.
Funniest thing is that I can’t even read Kotlin code. Like, at all. But I don’t have to — I steered the spec writing and reviewing, AI did the implementation. Replicated a month of work in a week.
You write the what and why, the AI writes the how. And if the spec is good enough, you don’t even need to understand the implementation language.
War story: the enshittification of Pippin
Now let me show you what happens when you do none of this in a brownfield codebase.
War story: the enshittification of Pippin
This happened around Aug of 2025, model in use — Claude Opus 3.
I have a small SaaS app — pippin.gg (moves discord messages between channels, people pay for it). The app was kinda crap — bad UX, bad error messages, Discord API behaving differently based on nitro status and server boost tier. Edge case hell.
What went right: With Claude I researched Discord docs, found the edge cases, refactored error handling, added utf-8 message splitting (turns out not everyone writes English in discord). A few hours of prompting across a few evenings. Would’ve been a month of work by hand.
What went wrong: The code ended up in a state where I could no longer understand what it does. Duplicate logic everywhere, mystery abstractions the LLM hallucinated into existence, dead code created “just in case.” Someone else’s fever dream, except I wrote it.
3-4 evenings to generate the slop. Over a dozen sessions across multiple weeks to clean it up. Every session I’d think “this is the last cleanup pass” and find another layer of nonsense underneath.
The ratio: 1:4. For every hour of prompting, four hours of unfucking. Sometimes the fastest path was git checkout -- src/ and starting over. Knowing when to throw your work away is a skill in itself.
Prompting is a skill too. Not “write better system prompts” — intuition. Gut feel for when the AI is confidently leading you off a cliff.
Same dev, different outcomes — why?
| Kotlin app | Pippin | |
|---|---|---|
| Approach | Spec-first, clean slate | Yolo prompting, brownfield |
| Specs | Backend spec + app behavior spec | None |
| Implementation plan | Yes, scaffolding-first | No, just “fix this bug” |
| Result | Production quality, stable | Working but unmaintainable |
| Cleanup time | Minimal — code was structured from the start | 4x the generation time spent unfucking it |
| Can I read the code? | No (Kotlin), but I don’t need to | It’s in Rust and I’m a Rust dev, but I was unable to |
The difference isn’t the AI. The difference is me. Specs, plans, and structure are what separate “AI-assisted engineering” from “expensive autocomplete that shits in your codebase”.
The pipeline is the cure. If I had done Pippin with proper research → design → plan → implement, I’d have a maintainable codebase instead of weeks of archaeological cleanup. That instinct — knowing when to nuke your context and start over with a proper spec — is worth more than any tool in this entire series.
The kanban board — managing the pipeline at scale
Great for one feature. But three features in flight, each at a different pipeline stage, and you can’t remember which needs a review and which is ready for impl? You put it on a board.
I use Linear. The agent moves items through pipeline stages:
Backlog → Researching → Designing → Implementing → Reviewing → Done
I as a developer am only involved in populating backlog, altho Claude Code will do it for me, I just prompt-explain what issues I want it to create.
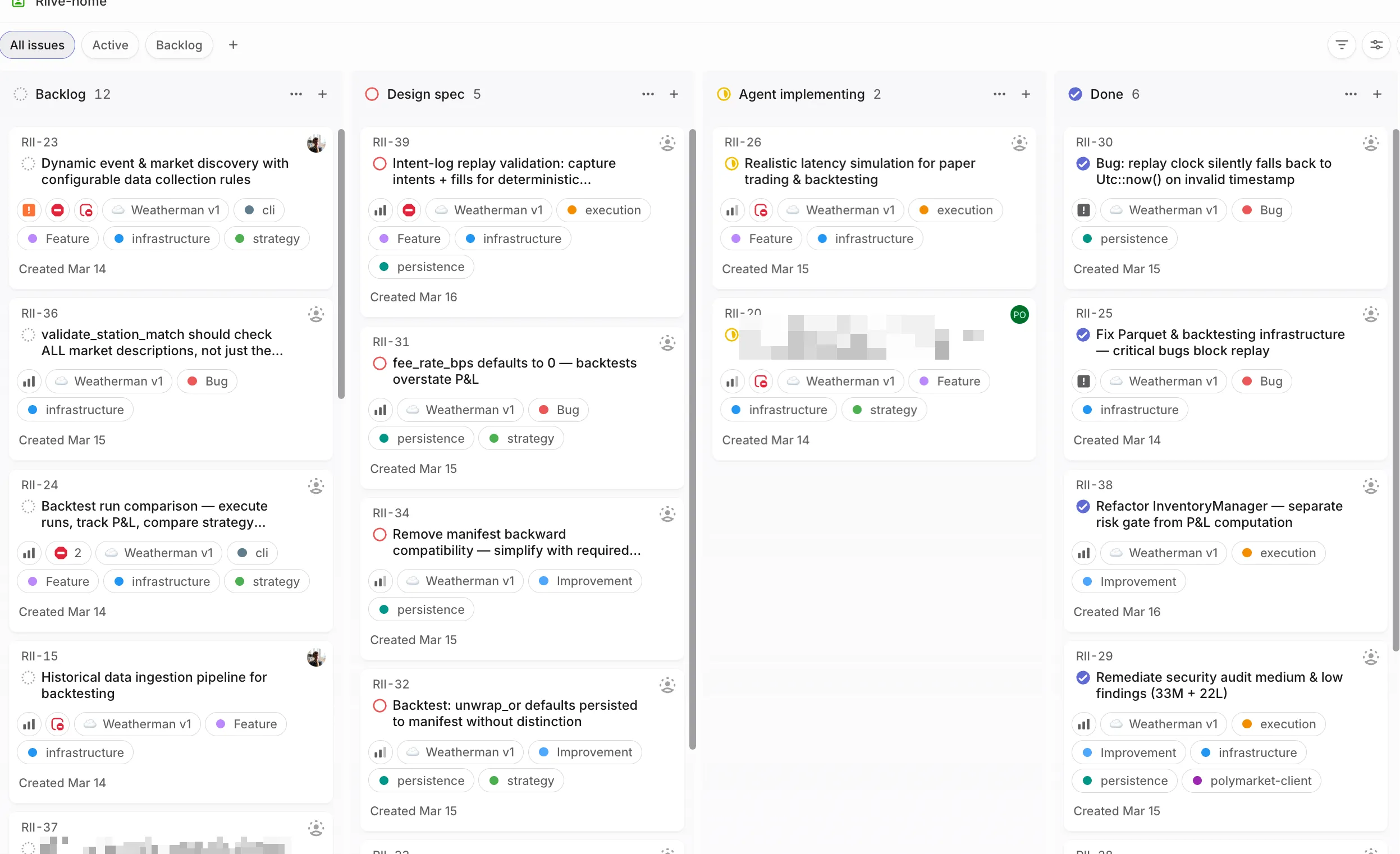
Setting up the Linear MCP is a one-liner: claude mcp add --transport http linear-server https://mcp.linear.app/mcp — then run /mcp in a session to authenticate via OAuth. Full instructions in the Linear MCP docs.
The full pipeline mapped to the board
-
Backlog: I describe the issue in plain language. Claude creates the ticket.
-
Researching: I use a custom “research codebase” skill for Claude to generate intermediate artifacts. The artifact is a markdown file that gets committed to the codebase. Ticket moves to next column.
-
Designing: I use brainstorming to create a design doc using the research artifacts. Another markdown file committed to the repo — success criteria, some test cases to create. Generally a high level doc of involved components, current state of the architecture, the desired state, some gotchas.
-
Implementing: The design doc gets turned into a concrete implementation plan with file and line references. Then subagent driven development in a git worktree. Subagents are essentially tiny sub-claudes with a fresh context window that implement specific tasks and report back to the main claude. This allows the main context window to not become too polluted with implementation details.
-
Reviewing: AI reviews before any human sees it. Local review prompt + /codex. On CI — CodeRabbit.
-
Done: Merged.
Where’s the human in all of this?
Focus your review time where it has the most leverage:
- Bad research → generates thousands of bad lines of code
- Bad plan → generates hundreds of bad lines
- Bad code → individual bad lines
You review research and design docs. AI handles code review and implementation. I can’t read 2000 lines of Rust diffs daily. But I can read 200 lines of a well-written implementation plan (this framing is from HumanLayer and it’s spot on).
Agent teams and code review
Agent teams for code review. Here’s the prompt pattern:
The code review prompt
The current PR adds new functionality for term ledgers. I want you to use agent teams with roles on security and correctness to review the feature branch - focus on mempool, gossip path, public API path, block validation. And dispatch /codex subcommand to get a second opinion. Create a markdown file as an artifact. Our main goal is to ensure that the changes to tx pricing work, that we properly compute term fee rewards on epoch block boundaries (and miners get rewarded), and that the rewards are also epoch-aware and use the correct pricing information when given out.
What makes this prompt work
Every piece is intentional:
- Agent teams — parallel investigation
- Assigned roles — security and correctness are different lenses
- Focus areas — mempool, gossip, public API, validation
- /codex — second opinion. Codex is better than Claude at analysis.
- Artifact format — only code review, nothing else
- The larger goal — so the review is grounded in what actually matters
Official docs on agent teams. On CI we also run CodeRabbit — nitpicky but catches real stuff:

Cross-model validation
You don’t write the codex prompt — Claude does. Claude knows what it found, what it’s unsure about, and what needs a second look. Let the models talk to each other. Here’s the command file:
codex.md — the full command file view source ↗
# Codex Second Opinion
Get a second opinion from OpenAI Codex on any question about this codebase — debugging, analysis, architecture, code review, or anything else.
## Arguments
The user's request is: $ARGUMENTS
## Instructions
Your job is to gather the right context, build a prompt that gives Codex enough understanding of this codebase to be useful, and then run `codex exec` with that prompt. Codex has zero knowledge of this codebase, so the context you provide is everything.
### Step 1: Gather Context
Read the Architecture Overview section of `CLAUDE.md` for a high-level understanding. Then, based on what the user is asking about, selectively read the files that are most relevant. Use these heuristics:
- **If actor services are involved**: read the service's message types and the `ServiceSenders`/`ServiceReceivers` pattern
- **If types crate is involved**: check wire formats (`BlockBody`, `BlockHeader`, `DataTransactionHeader`)
- **If consensus/mining is involved**: read the VDF + PoA section and shadow transaction patterns
- **If p2p is involved**: check gossip protocol routes and circuit breaker usage
- **If storage/packing is involved**: check chunk size constants and XOR packing invariants
- **If reth integration is involved**: check CL/EL boundary and payload building flow
If the user's request references specific files, diffs, or branches, read those too. Keep context focused — aim for 3-5 key files maximum.
### Step 2: Build the Prompt
Construct a single prompt string that includes:
1. **Architecture summary** — 2-3 sentences describing the relevant components and how they fit together
2. **Key conventions** — patterns that apply (e.g., "custom Tokio channel-based actor system, not Actix", "crypto crates compiled with opt-level=3")
3. **Relevant code** — inline the key snippets or file contents that Codex needs to see
4. **The user's request** — what they actually want Codex to analyze
### Step 3: Run Codex
```bash
codex exec --sandbox read-only "<constructed prompt>"
```
Run this in the background with a 300s timeout.
### Step 4: Monitor Progress
After launching codex in the background:
1. Wait ~30 seconds, then check the background task output using `TaskOutput` with `block: false`.
2. If there is new output, give the user a brief progress update.
3. Repeat every ~30 seconds.
4. If no new output appears for 60+ seconds and the task hasn't completed, warn the user that codex may be stuck and offer to kill it.
### Step 5: Present Results
Once codex finishes:
1. **Summary**: Concise summary of key findings, organized by category (only include categories with findings):
- Bugs and logic errors
- Security concerns
- Concurrency / actor system issues
- Code quality and style
- Performance considerations
2. **Raw output**: Complete codex output in a fenced code block.
3. **Counterpoints**: If you (Claude) disagree with any findings or think something was missed, add a "Claude's take" section. Only include this if you have a meaningful counterpoint.
### Error Handling
- If `codex` is not found, tell the user to install it: `npm install -g @openai/codex`
- If codex times out (5 minutes), show whatever partial output was captured and note the timeout
And here’s what it looks like when you actually invoke it — notice how I just tell Claude to “get /codex to review”, and it handles the rest:

Hooks and notifications
Alright so you’ve got multiple agents running, features in various pipeline stages, a board tracking everything — but you’re still alt-tabbing between terminals to check if something finished. That’s dumb. Let the tool tell you.
If you’re using Ghostty — Claude Code has native notification support. Agent finishes or hits a permission prompt? OS-level notification, no config needed. It just works.
For other terminals, set up custom notification hooks in your Claude settings. Same idea — Claude fires a hook when it needs attention instead of you polling like a maniac.
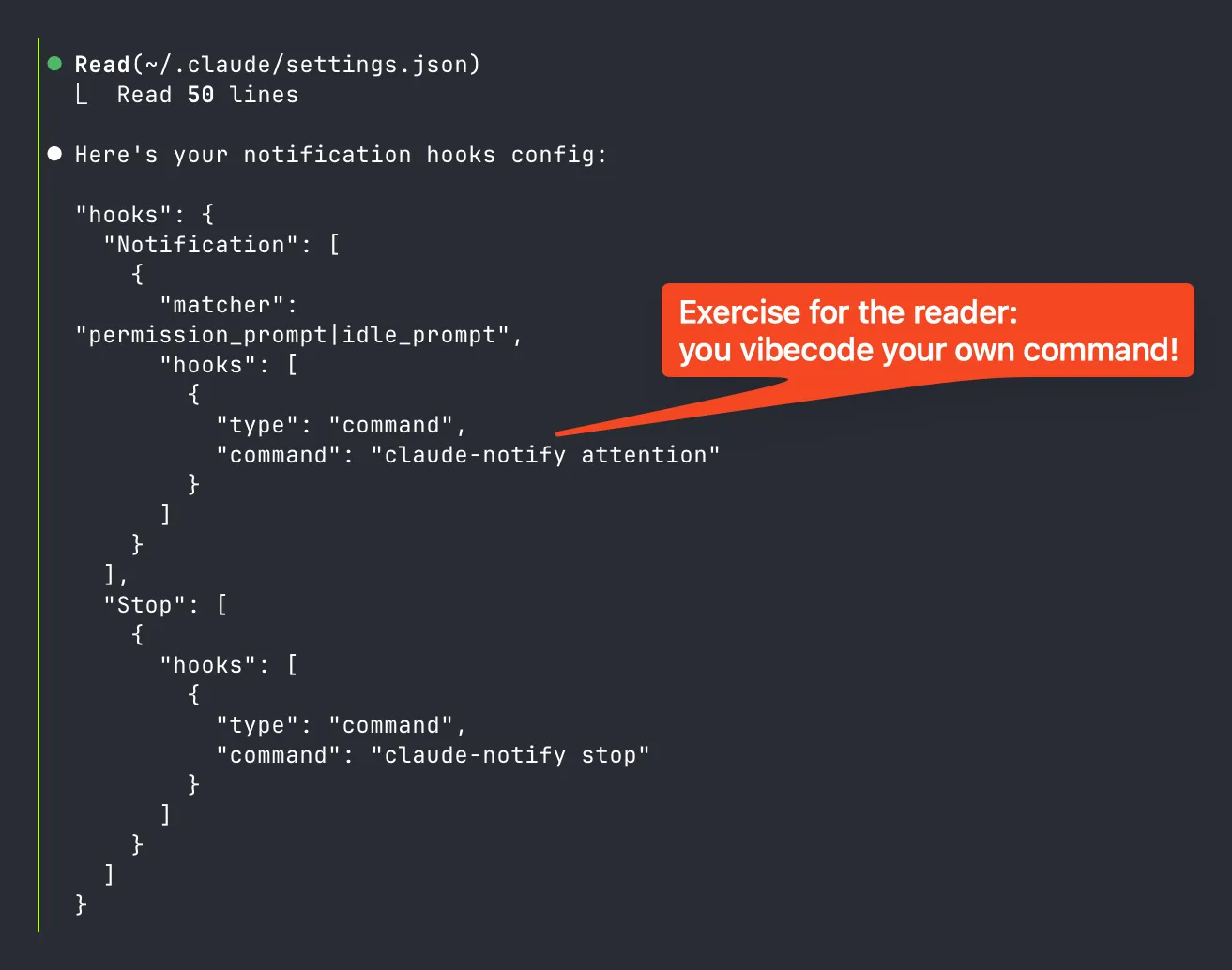
No more babysitting. Without notifications, “3 sessions running” just means “3 sessions you’re anxiously alt-tabbing to”.
Parallel feature development
My actual workflow
3 cmux sessions, same repo, different feature branches. Cycle between them. One agent is churning? Switch to another. Hooks ping me when a session needs attention.
I showed the session layout in Part 1 — same setup, just now with 3 feature branches instead of random side projects.
The numbers
Before AI I was able to ship solid 700-1k loc of feature on day 1, 500-1k loc of tests the second day, and then get the pr merged on 3rd day after addressing peer reviews. Now my cadence has gone to ~1 PR per day being merged, while also being able to cover much more ground.
Onboarding teammates
You don’t need to explain all the skills and commands. Set up the scaffolding, let Claude do the explaining.
For a side project I was onboarding a friend — sent him a Linear invite, told him to run /mcp, and said “ask Claude to explain the linear skill in the repo.” That was the entire onboarding. Up and running in minutes — the skills are self-documenting.
They don’t need to understand the full stack on day one. The knowledge compounds — every skill one person creates makes the whole team better.
Series wrap-up
So you started this series copy-pasting into ChatGPT and closing the tab. Or maybe you were where I was — mass-dismissing the whole thing as a fad for people who can’t code. Either way, you were playing single-player with autocomplete.
And now here we are. Agent teams doing parallel code review, specs that turn into production code in languages you literally cannot read, checking in on agents from your phone while walking. It’s a Tuesday.
The meta will keep changing — what I wrote here will probably be the “old way” in 2 months when a new model drops and everything shifts again. That’s just how it is. But the fundamentals? Those stick around:
- Manage your context. Everything is text. Everything competes for the same window. Keep it lean.
- Specs before code. Always. The pipeline is just structured thinking — that doesn’t go out of style.
- Review more than you type. You’re not a typist anymore. That’s the skill that compounds.
If you internalized even half of what’s in these three posts you’re already way ahead. And more importantly you’ve got the framework to keep adapting when the meta changes again. Which it will. Probably next week.
Now go claudemax something.